ComfyUI基础纯净版
最新版ComfyUI,包含多个热门v1.5模型,仅安装ComfyUI-Manager,预置SD3、XL、1.5、Lora等多个热门模型

想要运行这个应用吗?
- 帮助您专注于艺术创作,而非红色错误
- 由猫目社区来维护AIGC安装部署的复杂性
- 无需手动设置
- 具有惊艳的视觉效果
- 平台整合上万张高端显卡,一键启动
介绍
最新版的ComfyUI基础纯净版本,包含多个热门v1.5模型,仅安装ComfyUI-Manager、ComfyUI-Custom-Scripts、ComfyUI-Crystools,预置SD3、XL、1.5、Lora等多个热门模型。比较合适新手以及讲师使用,可以从零开始全面学习了解ComfyUI的界面、控件以及性能等。
应用使用教程
启动应用,进入应用
首先根据需求选择配置,然后启动应用,然后点击进入应用,可以看到内置默认工作流,如下如:
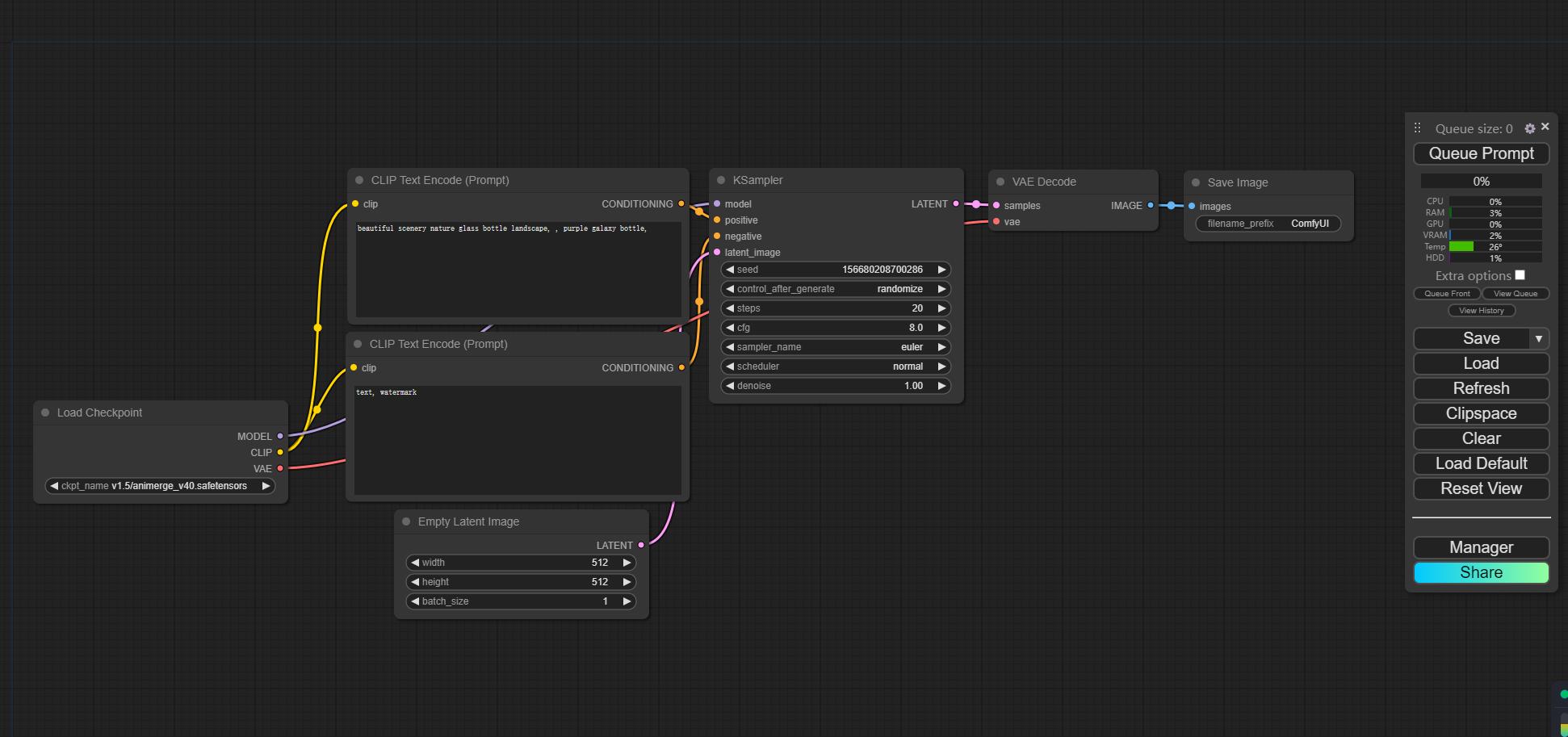
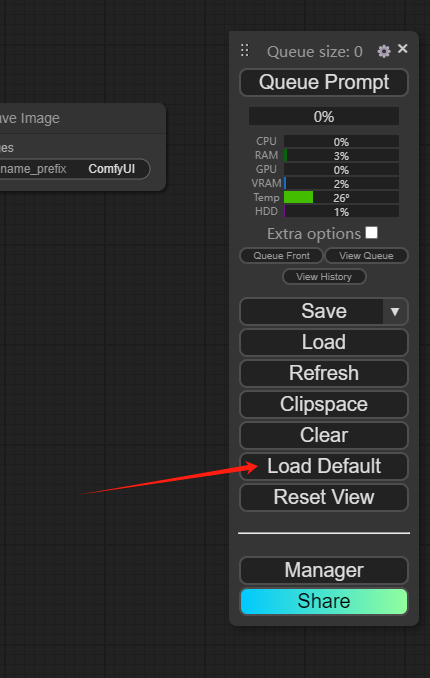
若是没有看到默认工作流,可以点击“Load Default” 按钮加载默认工作流
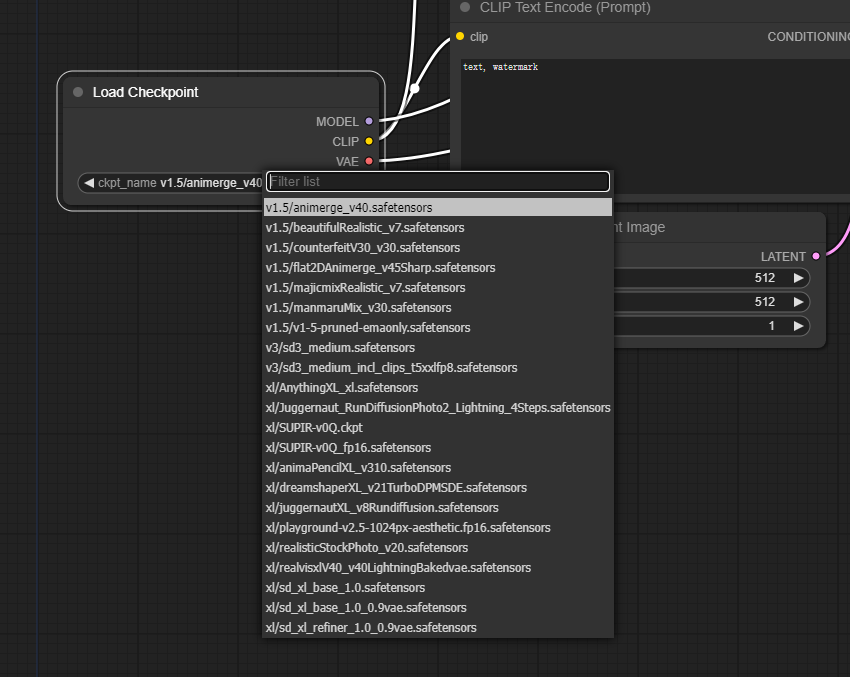
这里我们已经预置SD3、XL、1.5、Lora等多个热门模型,可以根据需求选择
手动上传模型
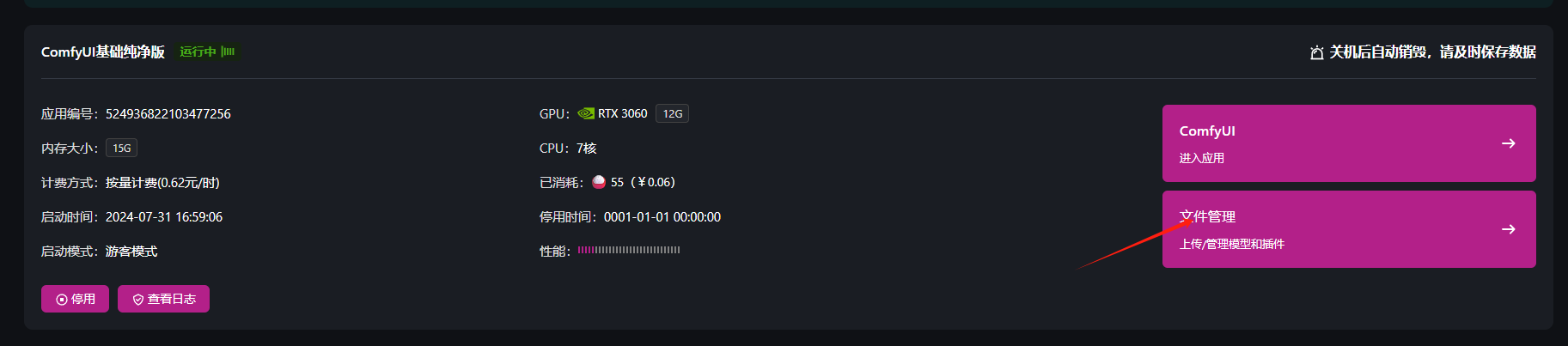
- 如果内置的模型中没有符合你的需求,可以将自己所需的模型或者插件进行上传。点击文件管理,进入文件跟目录下。
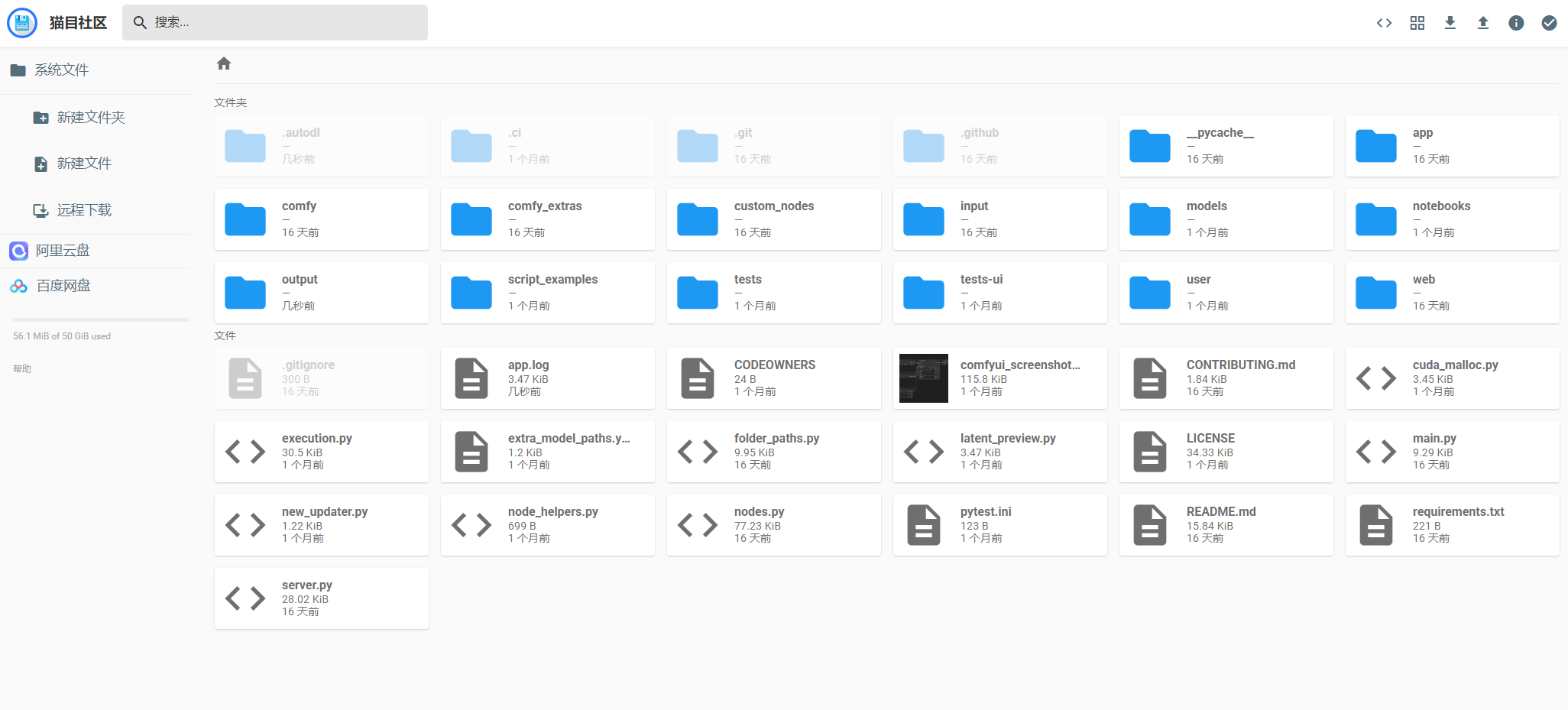
2. 需要上传模型,双击“models”目录,进入到模型管理目录
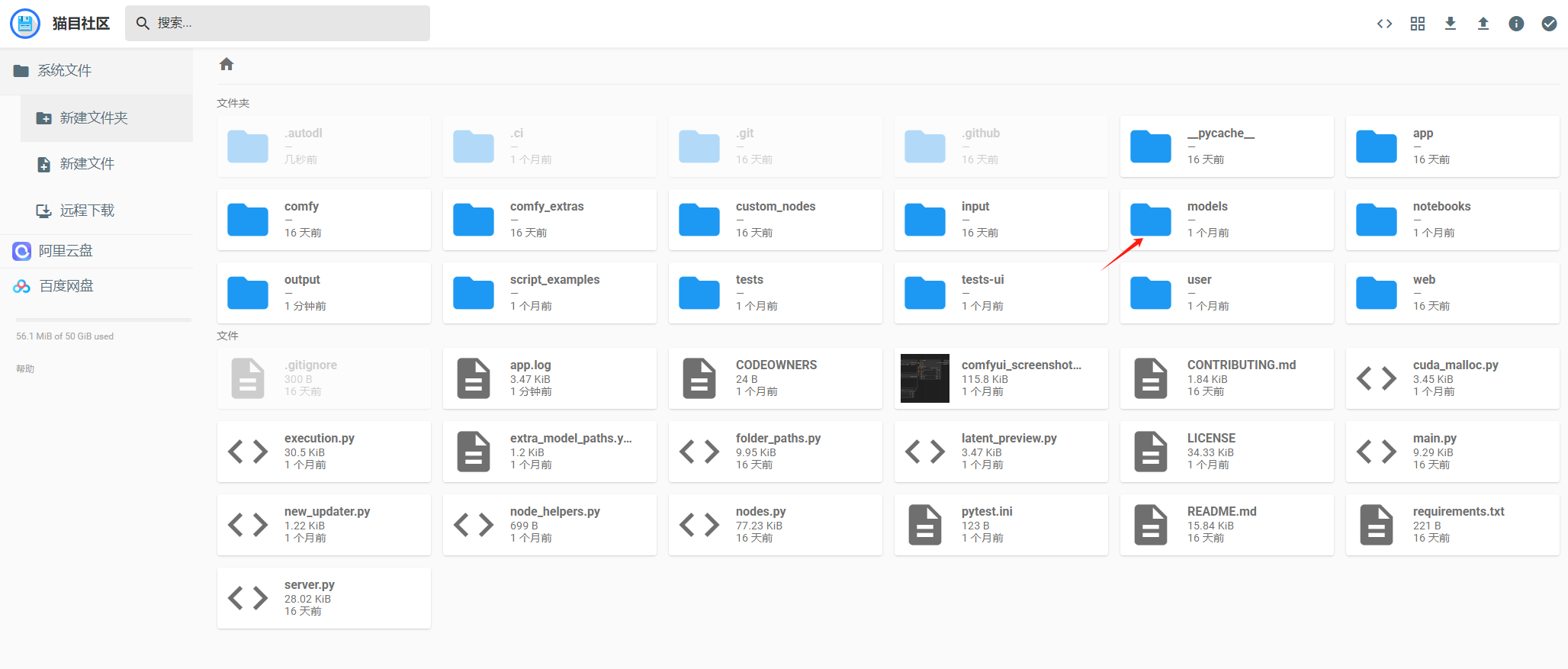
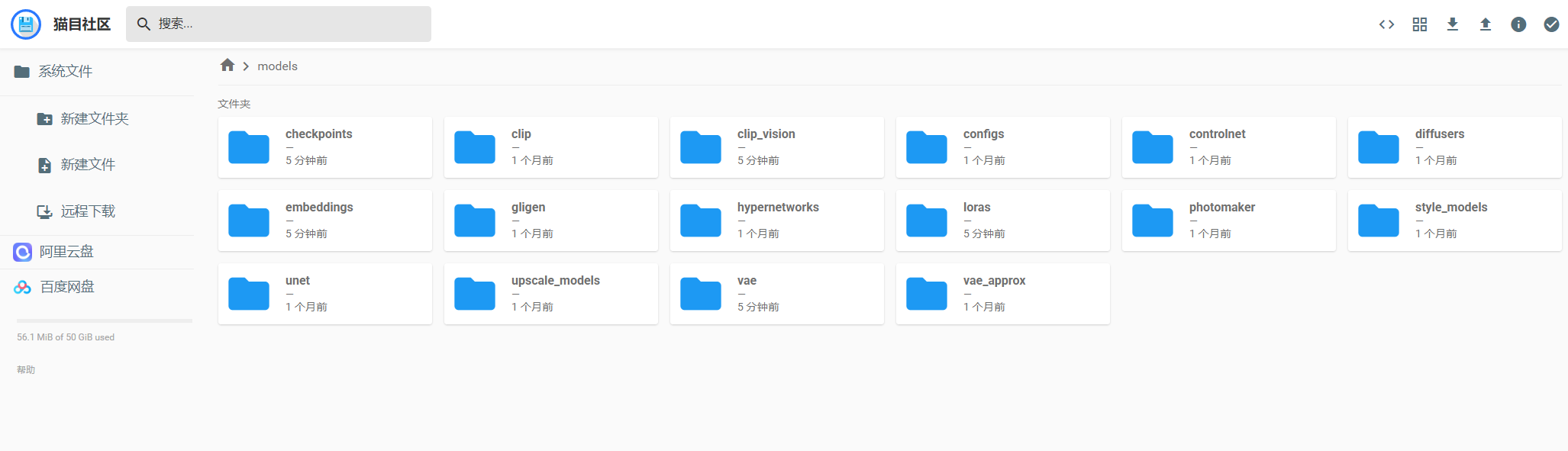
3. 将你需要的模型或者插件传到对应的目录
4. 点击上传箭头,选择需要需要上传的文件进行上传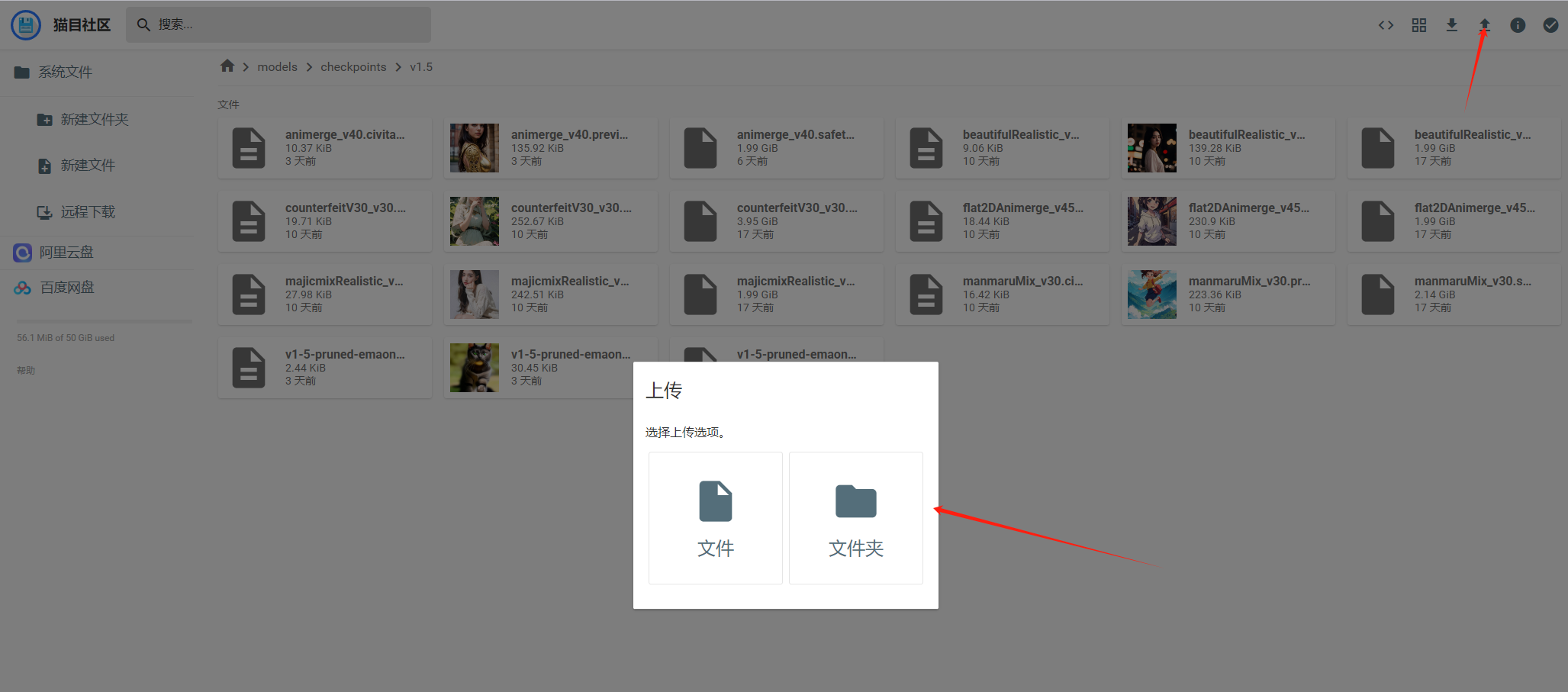
5. 回到ComfyUI界面,刷新一下界面,当选择模型时,就会看到你上传的模型。
已绑定阿里网盘或者百度云盘
如果你已经绑定了阿里网盘或者百度云盘,可以从网盘里直接传到文件目录里面,具体操作看阿里网盘或者百度云盘文件上传指南
ComfyUI基础教程
文生图
先从最简单的文生图工作流开始,这也是ComfyUI提供的默认的工作流,只要点击“Queue Prompt”按钮就能运行工作流了,然后就会看到有图片输出,如下图:
- 基本构建模块
ComfyUI 工作流程由两个基本构建模块组成:节点和边。
- 节点是矩形块,例如,加载Checkpoint、Clip Text Encoder(文本编码器)等。每个节点执行特定代码,并需要输入、输出和参数。
- 边是连接节点之间输入和输出的线。
- 基本控制
- 使用鼠标滚轮或双指捏合进行缩放
- 拖动并按住输入或输出点以在节点之间创建连接。
- 按住左键拖动可在工作区内移动。
文生图工作流详情
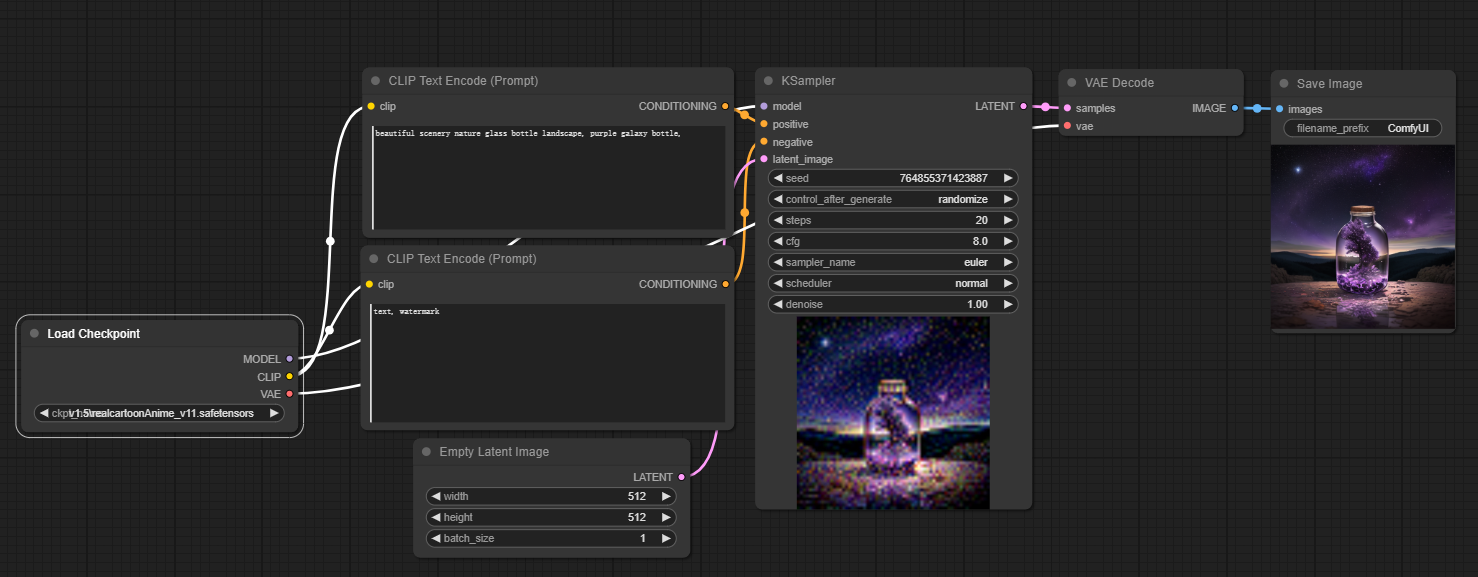
- 选择模型( Load Checkpoint)
首先,在Load Checkpoint节点中选择一个模型。点击模型名称以查看可用模型。如果点击模型名称没有反应,你可能需要上传自定义模型。Load Checkpoint节点对于选择Stable Diffusion模型至关重要,一个Stable Diffusion模型由三个主要组件组成:MODEL、CLIP和VAE。
- MODEL::MODEL组件是在潜在空间(Latent Space Transformation)中运行的噪声预测模型。它负责从潜在表示生成图像的核心过程。在ComfyUI中,Load Checkpoint节点的MODEL输出连接到KSampler节点,在那里进行反向扩散过程。KSampler节点使用MODEL迭代地去噪潜在表示,逐步细化图像,直到它与所需的提示匹配。
- CLIP:CLIP(Contrastive Language-Image Pre-training)是一个语言模型,用于预处理用户提供的正面和负面提示词。它将文本提示词转换为MODEL可以理解和使用的格式,以指导图像生成过程。在ComfyUI中,Load Checkpoint节点的CLIP输出连接到CLIP Text Encode节点。CLIP Text Encode节点接受用户提供的提示词,并将它们输入到CLIP语言模型中,将每个词转换为嵌入。这些嵌入捕捉词语的语义含义,使MODEL能够生成与给定提示词一致的图像。
- VAE:VAE(Variational AutoEncoder)负责在像素空间和潜在空间之间转换图像。它由一个将图像压缩到低维潜在表示的编码器和一个从潜在表示重建图像的解码器组成。在从文本到图像的过程中,VAE仅用于最后一步,将生成的图像从潜在空间转换回像素空间。ComfyUI中的VAE Decode节点接受KSampler节点(在潜在空间中运行)的输出,并使用VAE的解码器部分将潜在表示转换为像素空间中的最终图像。
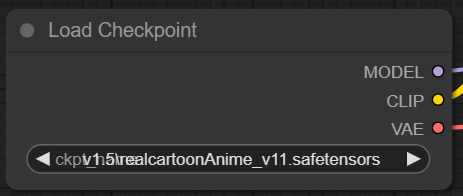
2. 输入正面提示和负面提示(CLIP Text Encode (Prompt))
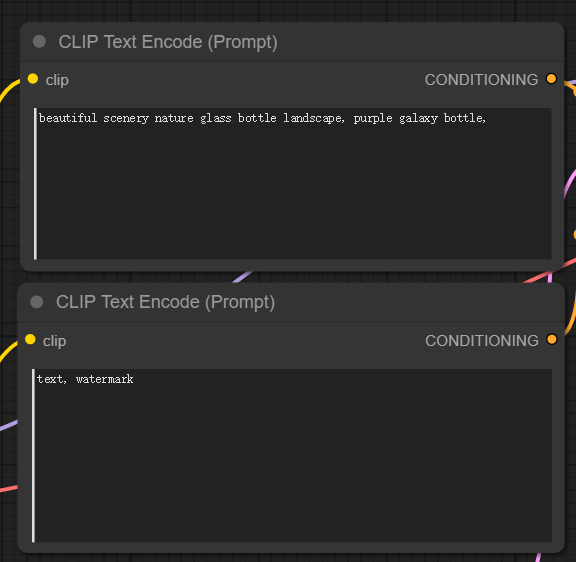
你将看到两个标记为CLIP Text Encode (Prompt) 的节点。上面是正向提示词连接到KSampler 节点的(positive)正输入,而反向提示词连接到(negative)负输入。
3. 修改图像大小(Empty Latent Image)
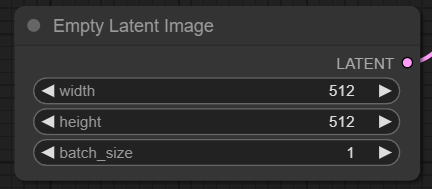
对于 SD v1.5 模型,推荐的大小是 512x512 或 768x768,而对于 SDXL 模型,最佳大小是 1024x1024。ComfyUI 提供了一系列常见的纵横比可供选择,如 1:1(方形)、3:2(横向)、2:3(纵向)、4:3(横向)、3:4(纵向)、16:9(宽屏)和 9:16(竖屏)。需要注意的是,潜在图像的宽度和高度必须是 8 的倍数,以确保与模型架构的兼容性。
4. 采样器( KSampler)
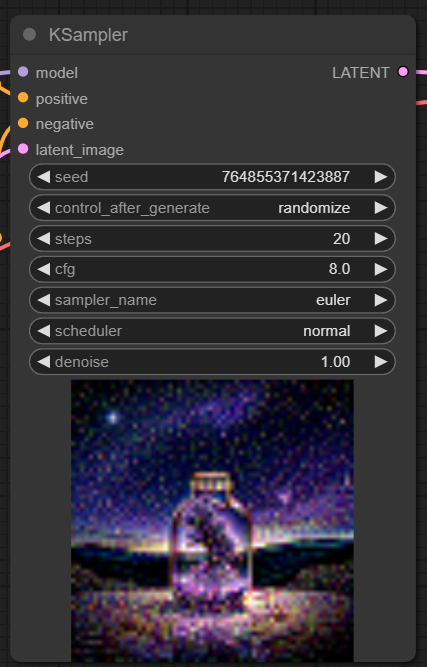
ComfyUI中的KSampler节点是Stable Diffusion中图像生成过程的核心。它负责对潜在空间中的随机图像进行去噪,以匹配用户提供的提示。
- Seed: 种子值控制最终图像的初始噪声和构图。通过设置特定的种子,用户可以获得可重复的结果,并在多次生成中保持一致性。
- Control_after_generation: 这个参数决定了每次生成后种子值的变化方式。它可以设置为随机(每次运行生成一个新的随机种子)、递增(将种子值增加1)、递减(将种子值减少1)或固定(保持种子值不变)。
- Step: 采样步数决定了细化过程的强度。较高的值会产生较少的伪影和更详细的图像,但也会增加生成时间。
- Sampler_name: 这个参数允许用户选择KSampler使用的特定采样算法。不同的采样算法可能会产生略有不同的结果,并具有不同的生成速度。
- Scheduler: 调度器控制每一步去噪过程中噪声水平的变化。它决定了从潜在表示中去除噪声的速率。
- Denoise: 去噪参数设置去噪过程应该消除的初始噪声量。值为1意味着所有噪声将被去除,从而产生一个干净和详细的图像。
5. 图像解码 (VAE Decoder)
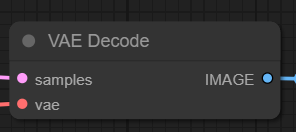
图像解码器,也称为 VAE 解码器,负责从潜在表示中重建图像,将其还原为像素空间中的图像。
图生图
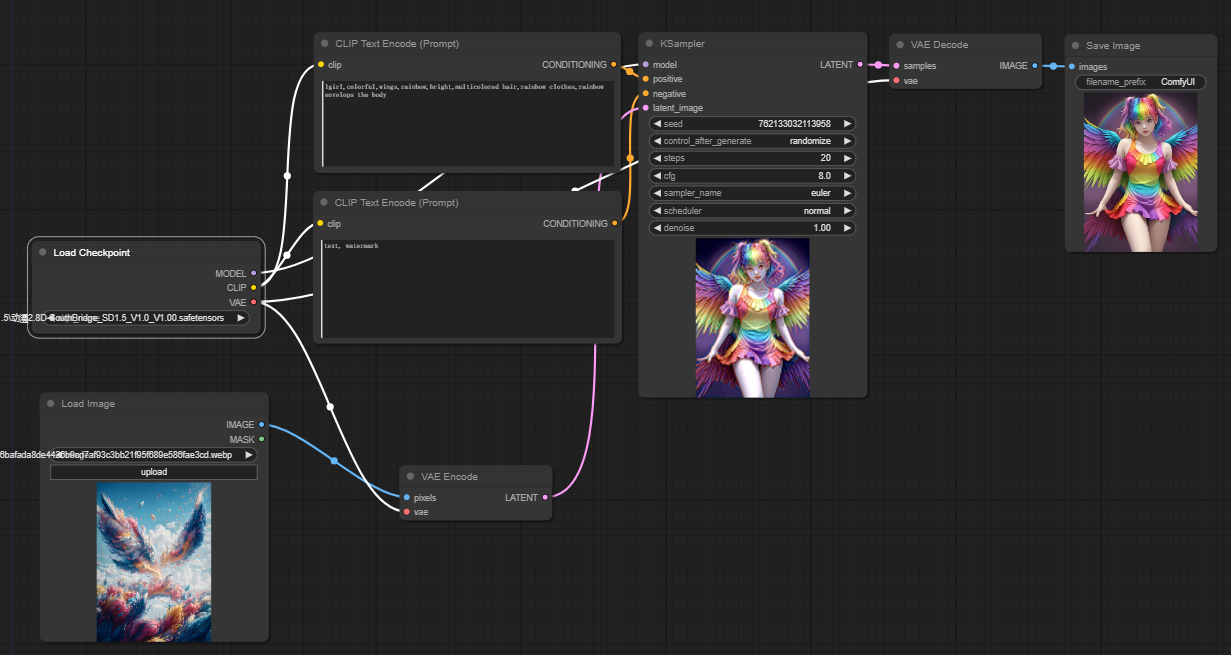
根据上面文生图,再来看看图生图就会觉得简单多了。只需要加载一个张图片(Load Image)作为提示词。流程还是一样的。
- 选择Checkpoint模型
- 上传图片作为提示词
- 修改正面提示词和反面提示词
- 修改采样器( KSampler)参数
- 按Queue Prompt开始生成
局部修复(Inpainting )
ComfyUI Inpainting 是一种利用人工智能技术在图像处理领域进行修复和填补缺失或损坏区域的技术。Inpainting(修复、填补)旨在根据图像的上下文生成和填补丢失或损坏的部分,使其看起来与原图自然融合。
具体来说,ComfyUI Inpainting 的主要功能和应用:
- 修复图像:修复因损坏、刮擦或老化导致的图像缺陷。例如,修复老旧照片中的破损区域,使其恢复原貌。
- 移除不需要的元素:从图像中移除不需要的对象或人物,并使用周围的内容填补空白。例如,去除照片中的电线、标志或其他干扰物。
- 增强图像:在图像中添加或修改某些部分,以增强图像的效果。例如,给人物图像添加缺失的部分或者修正某些错误。
- 生成缺失内容:根据图像的上下文生成缺失的内容。例如,填补被遮挡的部分,生成与周围环境一致的内容。
使用comfyui可以快速修复进行局部修复,如下工作流:
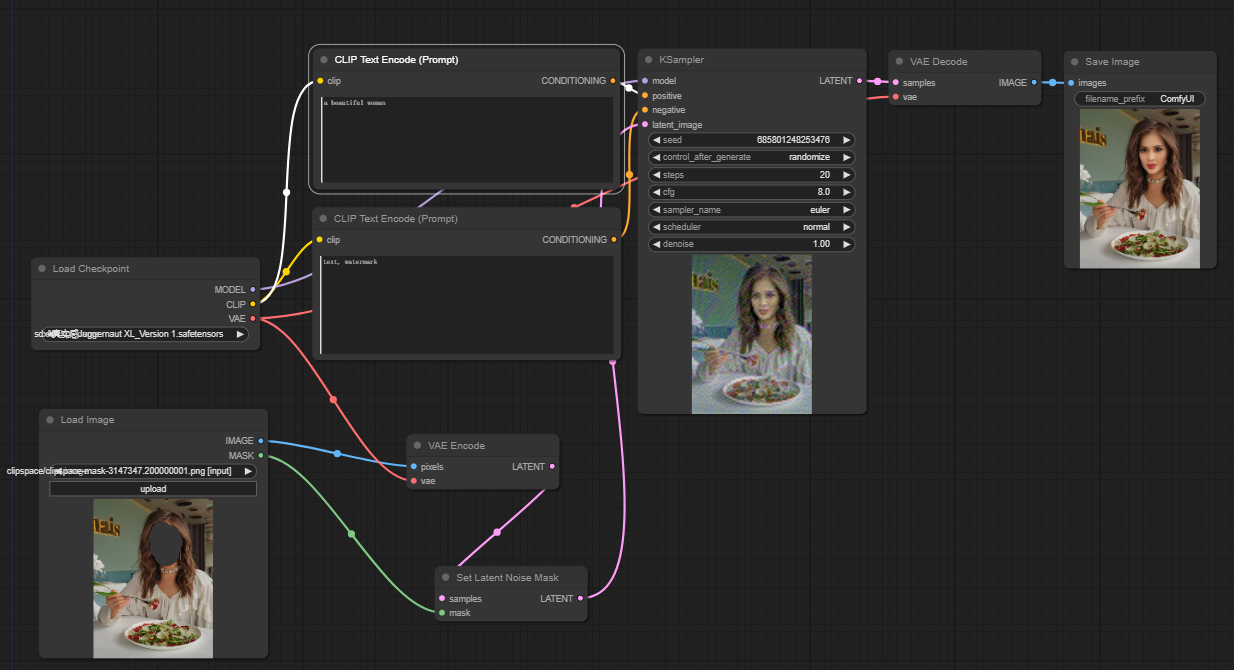
使用步骤:
- 上传想要修复的照片
- 右键单击图像,选择"Open in MaskEditor"。
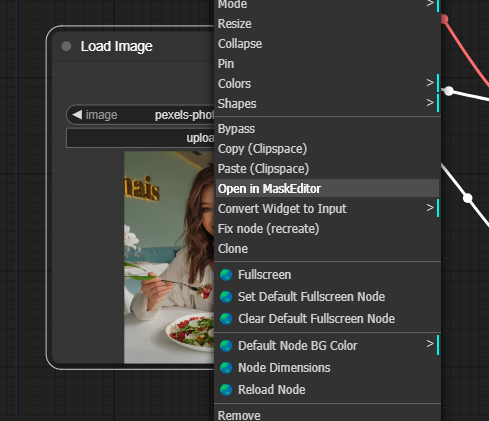
在要重新生成的区域上绘制遮罩,然后单击"Save to node"。
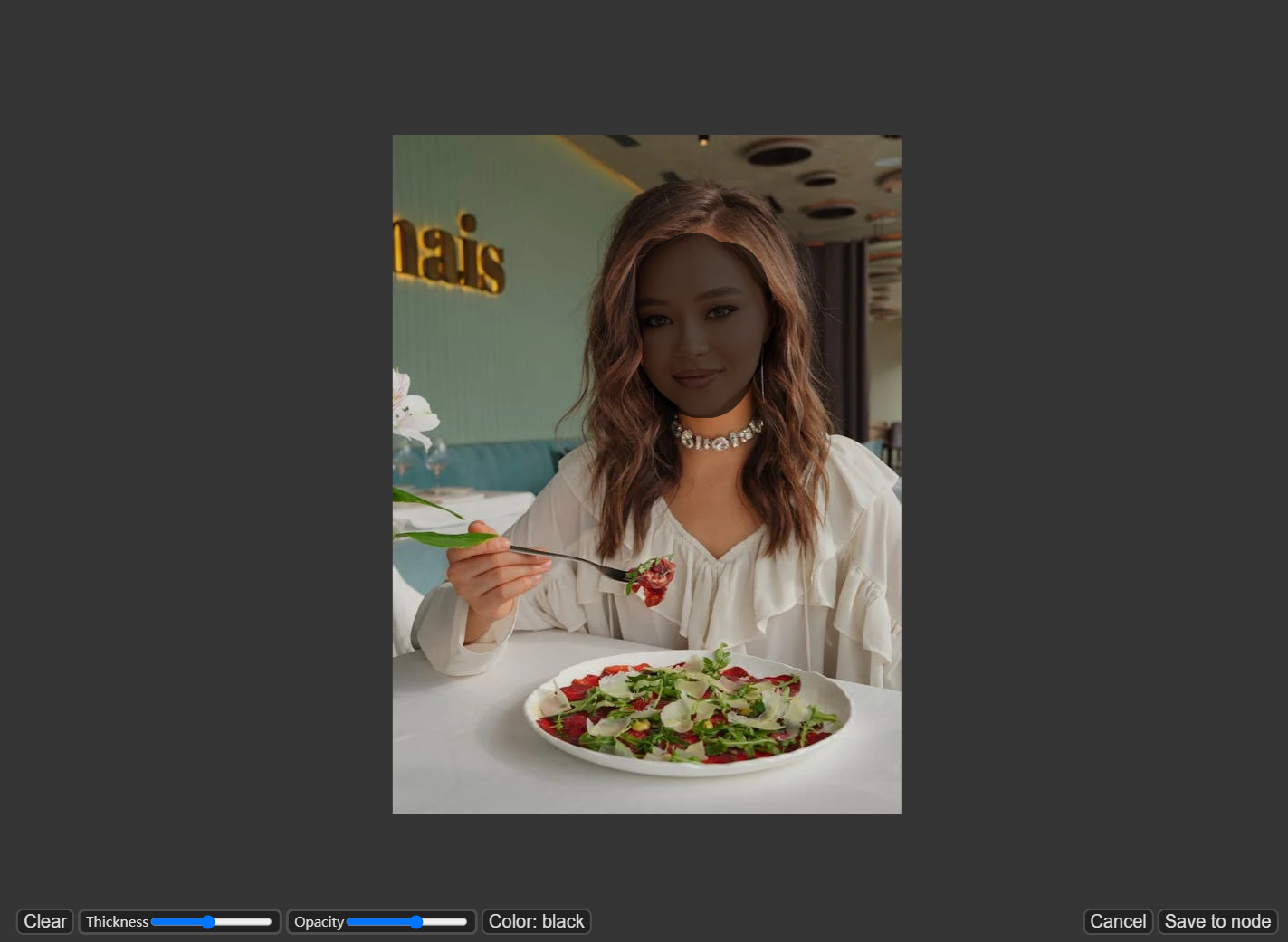
3. 选择一个Checkpoint模型:
- 这个工作流只适用于标准的Stable Diffusion模型,不适用于Inpainting模型。
- 如果你想利用inpainting模型,请将"VAE Encode"和"Set Noise Latent Mask"节点切换为专门为inpainting模型设计的"VAE Encode (Inpaint)"节点。
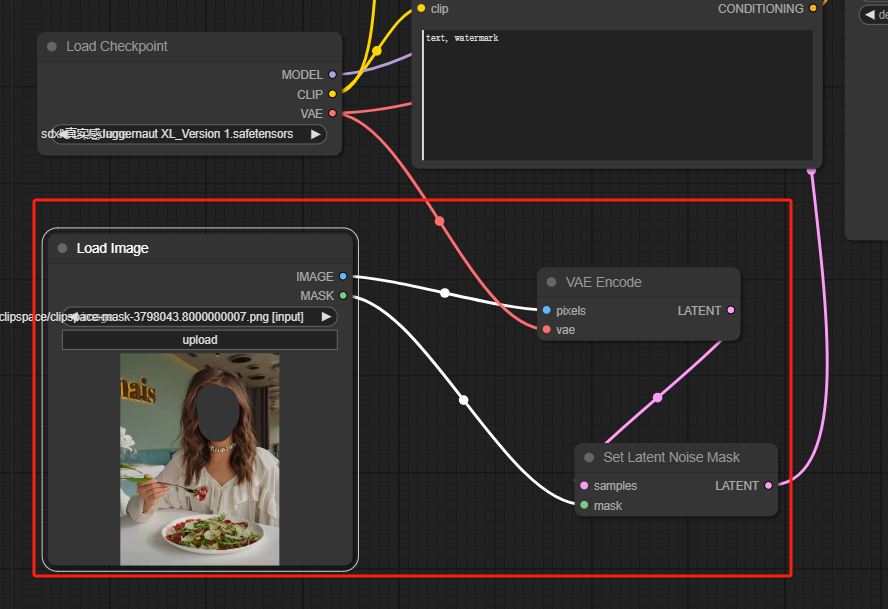
4. 填写正向提示词,生成你想要的效果
5. 调整采样器参数,比如denoise设置为0.6-0.7
外绘(Outpainting)
ComfyUI Outpainting 是指使用 ComfyUI(通常是一个基于人工智能的图像处理工具或用户界面)来实现图像扩展的技术。Outpainting(外绘)是一种生成性填充技术,可以在原始图像的基础上向外扩展,添加额外的图像内容。具体来说,Outpainting 可以理解为在现有图像的边界之外,生成和填充新的内容,使得图像看起来像是自然扩展的一部分,而不会显得突兀或不协调。
ComfyUI Outpainting 的主要应用和特点:
- 图像扩展:可以在不改变原始图像内容的情况下,扩展图像的尺寸。例如,可以将一张方形的图像扩展为长方形,或者将边缘进行填充以适应新的画布大小。
- 保持风格一致性:生成的扩展部分通常会与原图的风格保持一致,使得整体图像看起来和谐统一。
- 自动化和用户友好:ComfyUI 可能提供直观的用户界面,使用户可以方便地指定扩展方向和尺寸,无需深入了解底层的技术细节。
- 生成性对抗网络(GAN)或其他AI技术:Outpainting 通常基于 GAN 或其他深度学习模型,这些模型能够理解和生成复杂的图像内容。
例如下面的扩展工作流:
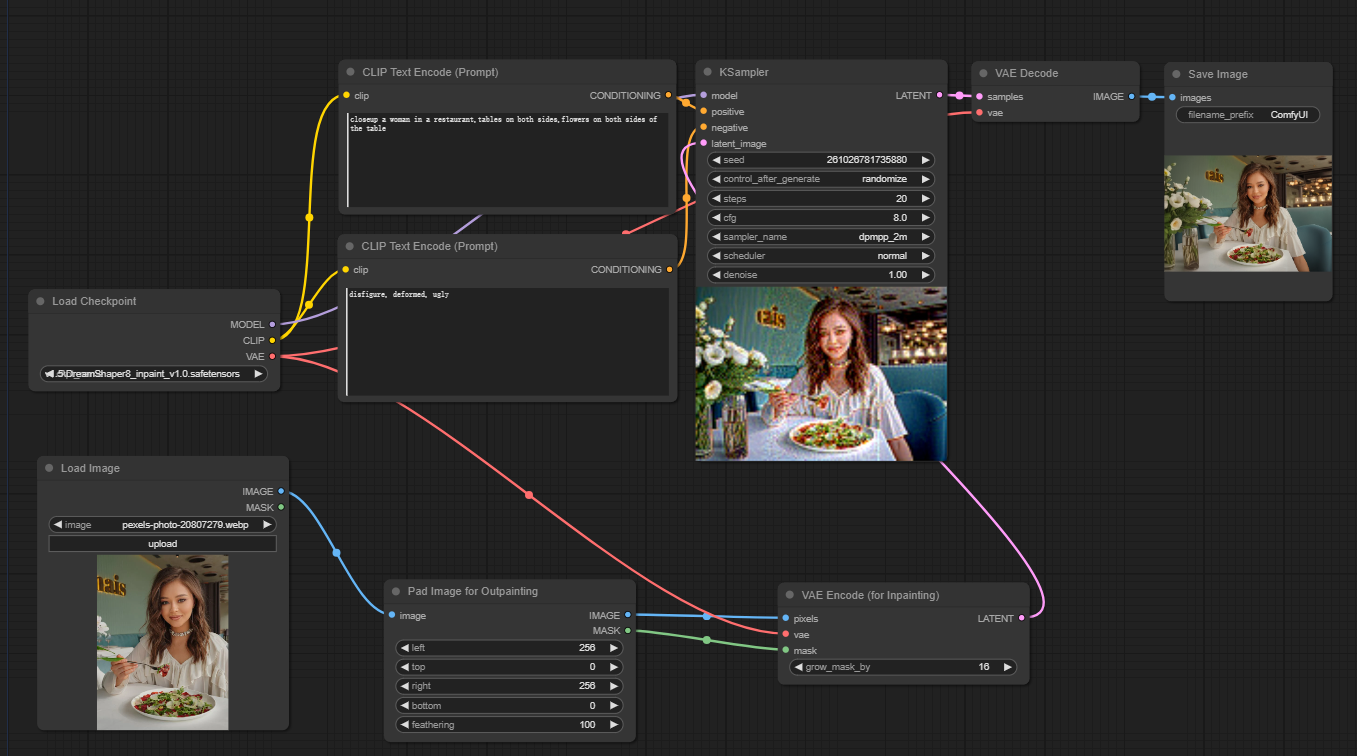
使用步骤:
- 选择需要扩展的图片
- 选择一个比较好的painting模型
- 使用Pad Image for Outpainting节点
- 设置outpainting的参数left, top, right, bottom: 指定每个方向上要扩展的像素数。feathering: 调整原始图像和outpainting区域之间过渡的平滑度。较高的值会创建更渐进的混合,但可能会引入模糊效果。
- 在CLIP Text Encode (Prompt)节点输入正向提示词和反向提示词,使生成效果更精确
- 使用VAE Encode (for Inpainting)节点,调整参数调整grow_mask_by参数以控制outpainting遮罩的大小。建议使用大于10的值以获得最佳结果。
- 调成采样器(KSampler)的参数,denoise越大,想象力就更丰富。
结语
祝您在猫目平台上创作愉快!这将是给我们的最大的鼓励。