Meta-Llama-3.1-8B-Instruct
由Meta推出的LLaMa3系列最新版本。LLaMa-3.1支持128K上下文,以及8种不同语言。本模型为LLaMa-3.1系列中的8B instruct版本。

想要运行这个应用吗?
- 帮助您专注于艺术创作,而非红色错误
- 由猫目社区来维护AIGC安装部署的复杂性
- 无需手动设置
- 具有惊艳的视觉效果
- 平台整合上万张高端显卡,一键启动
介绍
LlaMa 3(LLaMa 是“Large Language Model Meta AI”的缩写)Facebook母公司Meta开发的第三代大型语言模型。这些模型旨在在自然语言理解和生成方面表现出色,并且在前代模型的基础上进行了多项改进。现在LlaMa 3.1在Hugging Face上已有八个开源权重模型(3个基础模型和5个微调模型)。
Llama 3.1有三种大小:8B适用于在消费级GPU上高效部署和开发,70B适用于大规模AI原生应用,405B适用于合成数据、LLM作为评审或蒸馏。这三种模型都有基础版和指令微调版。
除了六个生成模型外,Meta还发布了两个新模型:Llama Guard 3和Prompt Guard。Prompt Guard是一个小型分类器,能够检测提示注入和越狱。Llama Guard 3是一个安全保护模型,可以分类LLM输入和生成的内容。
Llama 3.1有哪些新功能?
在前任模型的基础上,Llama 3.1增加了一些关键新功能:
- 128K tokens的大上下文长度(相比原来的8K)
- 多语言能力
- 工具使用能力
- 拥有4050亿参数的非常大的密集模型
- 更宽松的许可证
让我们深入了解这些新功能!
Llama 3.1发布了基于Llama 3架构的六个新开放LLM模型。它们有三种规格大小:8B、70B和405B参数,每种都有基础版(预训练)和指令微调版。所有版本都支持128K tokens的上下文长度,并支持包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语在内的8种语言。Llama 3.1继续使用Grouped-Query Attention (GQA),这是一种高效表示,有助于处理更长的上下文。
具体型号包括:
- Meta-Llama-3.1-8B: 基础8B模型
- Meta-Llama-3.1-8B-Instruct: 基础8B模型的指令微调版
- Meta-Llama-3.1-70B: 基础70B模型
- Meta-Llama-3.1-70B-Instruct: 基础70B模型的指令微调版
- Meta-Llama-3.1-405B: 基础405B模型
- Meta-Llama-3.1-405B-Instruct: 基础405B模型的指令微调版
除了这六个语言模型外,还发布了Llama Guard 3和Prompt Guard。
Llama Guard 3是Llama Guard家族的最新版本,基于Llama 3.1 8B微调而成。它适用于生产场景,支持128k的上下文长度和多语言能力。Llama Guard 3可以分类LLM的输入(提示)和响应,以检测在风险分类中被认为不安全的内容。 另一方面,Prompt Guard是一个小型的279M参数基于BERT的分类器,能够检测提示注入和越狱。它在大量攻击语料库上训练,建议在特定应用数据上进一步微调。
Llama 3.1相比Llama 3的一个新特点是指令模型进行了工具调用的微调,以适应代理性使用场景。内置了两个工具(搜索和Wolfram Alpha的数学推理),可以通过自定义JSON函数扩展。
Llama 3.1模型在定制的GPU集群上训练了超过15万亿tokens,总计39.3M GPU小时(8B模型1.46M小时,70B模型7.0M小时,405B模型30.84M小时)。我们不知道具体的训练数据集构成,只能推测它有更多样的多语言数据集。Llama 3.1 Instruct优化了指令遵循,训练数据包括公开可用的指令数据集,以及通过监督微调(SFT)和人类反馈强化学习(RLHF)生成的超过2500万个合成示例。Meta开发了基于LLM的分类器,在数据混合创建过程中筛选和优化高质量的提示和响应。
关于许可证条款,Llama 3.1的许可证与之前版本非常相似,但有一个关键区别:它允许使用模型输出改进其他LLM。这意味着即使使用不同的模型也可以进行合成数据生成和蒸馏!这对于405B模型尤为重要,如后文所述。许可证允许再分发、微调和创建衍生作品,仍要求衍生模型在名称前包含“Llama”,且任何衍生作品或服务必须提及“Built with Llama”。有关完整细节,请务必阅读官方许可证。
官方许可证:https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct/blob/main/LICENSE
Llama 3.1 需要多少内存?
运行Llama 3.1需要仔细考虑硬件资源,这里细分了三种模型大小的训练和推理内存要求。
推理内存要求
对于推理,内存需求取决于模型大小和权重的精度。下表显示了不同配置所需的大致内存:
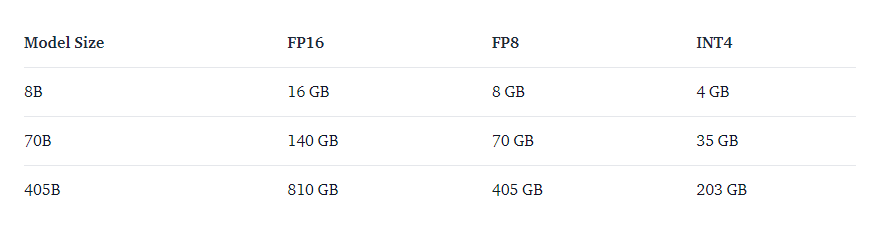
注意:上述数字表示仅加载模型检查点所需的 GPU VRAM。它们不包括内核或 CUDA 图的 Torch 保留空间。
例如,H100 节点(8x H100)有 ~640GB 的 VRAM,因此 405B 模型需要在多节点设置中运行或以较低的精度运行(例如 FP8),这是推荐的方法。
请记住,较低的精度(例如 INT4)可能会导致准确性有所损失,但可以显著降低内存需求并提高推理速度。除了模型权重之外,您还需要将 KV 缓存保留在内存中。它包含模型上下文中所有标记的键和值,因此在生成新标记时无需重新计算它们。特别是在利用较长的可用上下文长度时,它成为一个重要因素。在 FP16 中,KV 缓存内存要求为:
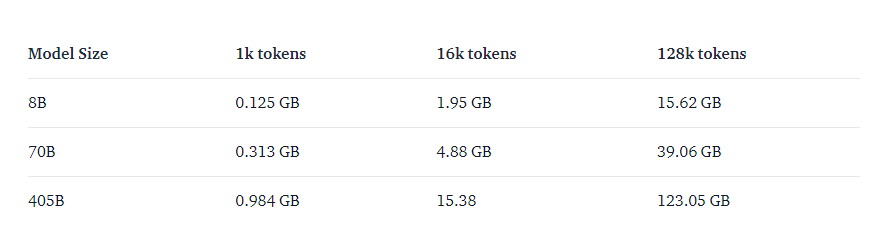
特别是对于小模型,当接近上下文长度最大值时,缓存使用与权重一样多的内存。
训练记忆要求
下表概述了使用不同技术训练 Llama 3.1 模型的大致内存要求:
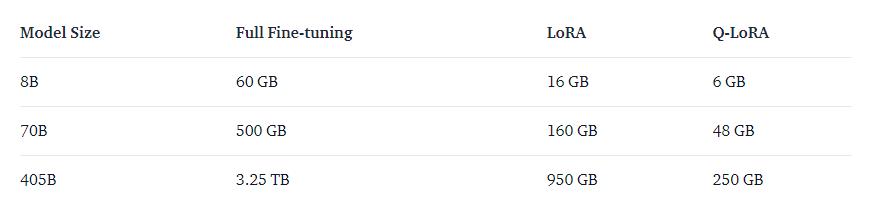
LLaMa 3 代表了大型语言模型发展的重要进步,结合了最先进的技术和庞大的数据,提供了多功能且强大的 AI 能力。
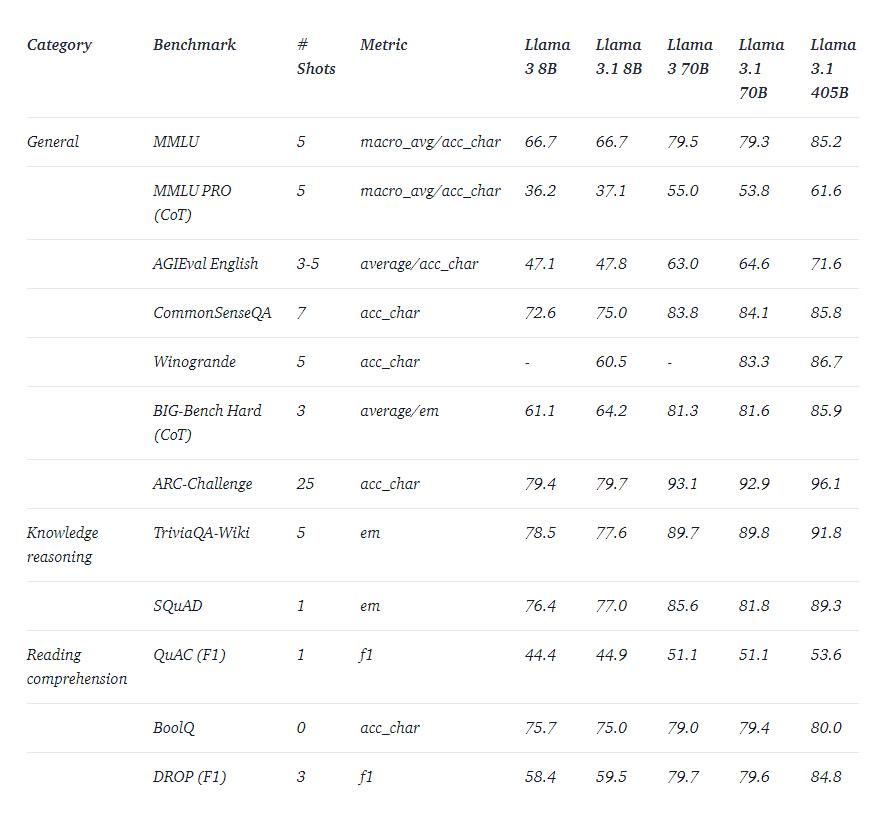
Llama 3.1的评估
以下是官方给出的一些评估资料:
如何使用Llama 3.1
基础模型没有特定的提示格式。像其他基础模型一样,它们可以用于继续输入序列,生成合理的后续内容,或者用于零样本/少样本推理。它们也是微调自身用例的良好基础。
指令版本支持四种角色的对话格式:
- system:设置对话的上下文。可以包括规则、指南或必要的信息,以帮助有效响应。还用于在适当时启用工具使用。
- user:用户的输入、命令和问题。
- assistant:助手的回应,基于‘system’和‘user’提示中提供的上下文。
- ipython:Llama 3.1中引入的新角色。这个角色用于当工具调用返回结果时的输出。
指令版本使用以下对话结构进行简单对话:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_msg_1 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1 }}<|eot_id|>
Llama 3.1指令模型现在支持工具调用,包括三个内置工具(brave_search, wolfram_alpha和code_interpreter)以及通过JSON函数调用的自定义工具。内置工具使用Python语法。用于函数调用的Python代码输出能力是code_interpreter工具的一部分,必须在系统提示中使用Environment关键字启用。
总结
Llama 3.1 提供了更高效的推理、微调和合成数据生成能力,适用于各种AI应用和开发需求。其指令模型支持四种角色的对话格式,增强了与用户的互动体验,立刻在猫目平台体验一下吧!