SD WebUI基础纯净版
AUTOMATIC1111官方最新版V1.10.1,预置SD3、XL、1.5、ControlNet、Lora等多个热门模型

想要运行这个应用吗?
- 帮助您专注于艺术创作,而非红色错误
- 由猫目社区来维护AIGC安装部署的复杂性
- 无需手动设置
- 具有惊艳的视觉效果
- 平台整合上万张高端显卡,一键启动
介绍
SD WebUI基础纯净版是一个未安装任何插件的初始版本,非常适合初学者或讲师使用。这个版本提供了一个干净、简洁的界面,让用户能够快速上手并熟悉基本功能,而不必为众多插件和复杂设置感到困扰。对于初学者来说,这意味着可以专注于学习和理解WebUI的核心概念和操作,而不会被多余的功能分散注意力。对于讲师来说,基础纯净版提供了一个理想的教学环境,可以清晰地演示每一个步骤和功能,帮助学生更好地理解和掌握基础知识。总的来说,SD WebUI基础纯净版是一个功能明确、使用简便的理想选择。
其次基础版里面也预置SD3、XL、1.5、ControlNet、Lora等多个热门模型。
Stable Diffusion的配置要求
- 最低配置
- 显卡:Nvidia独显 4G+
- 内存:8G+
- 硬盘:剩余空间20G+
- 推荐配置
- 显卡:Nvidia独显 8G+
- 内存:16G+
- 硬盘:剩余空间40G+
SD WebUI基础使用教程
Stable Diffusion扩展安装
- 首先,打开Stable Diffusion webUI的界面
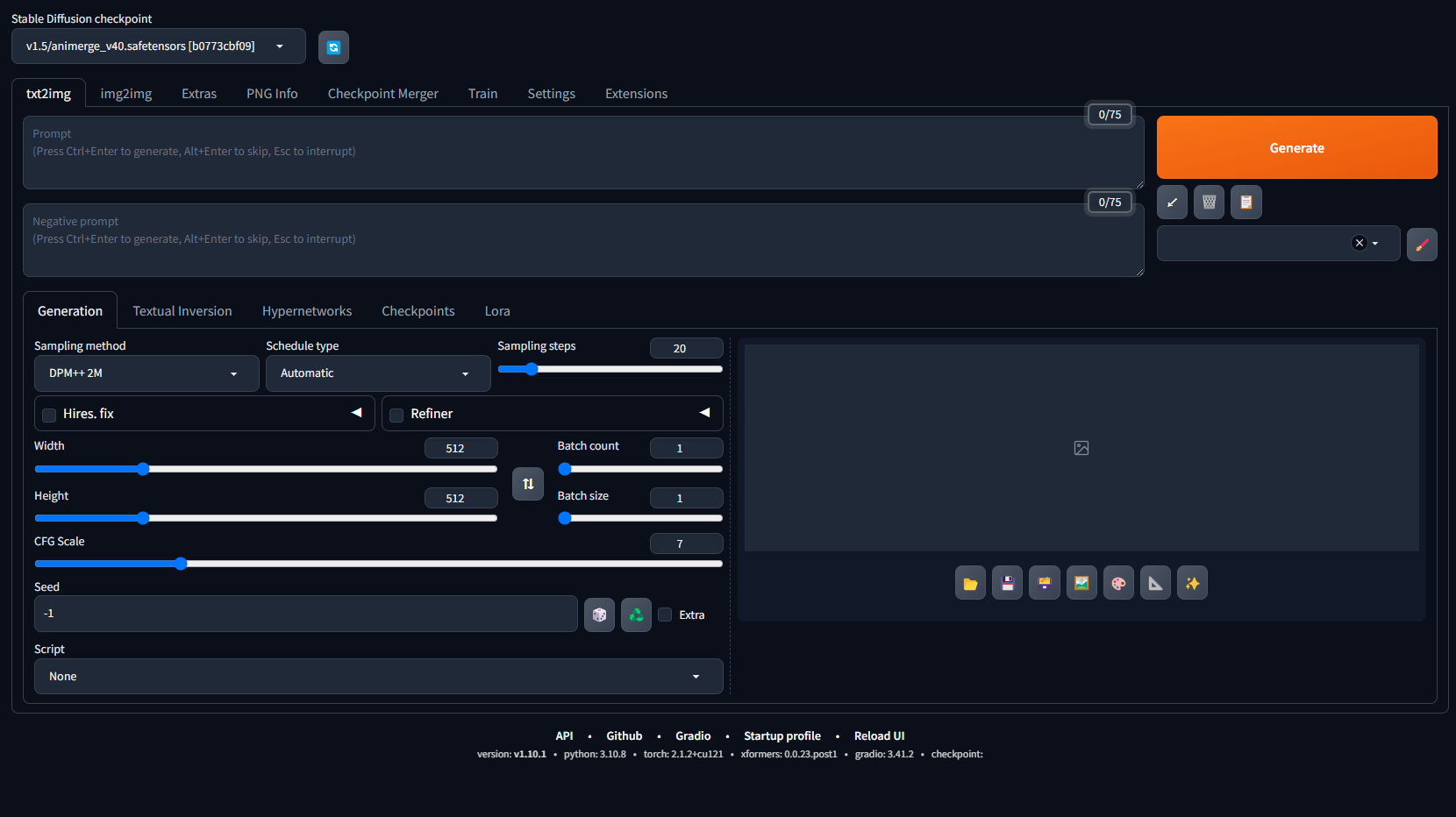
2. 点击Extensios(扩展)选项卡→点击Available(可用)选项卡→点击Load from(加载自)按钮
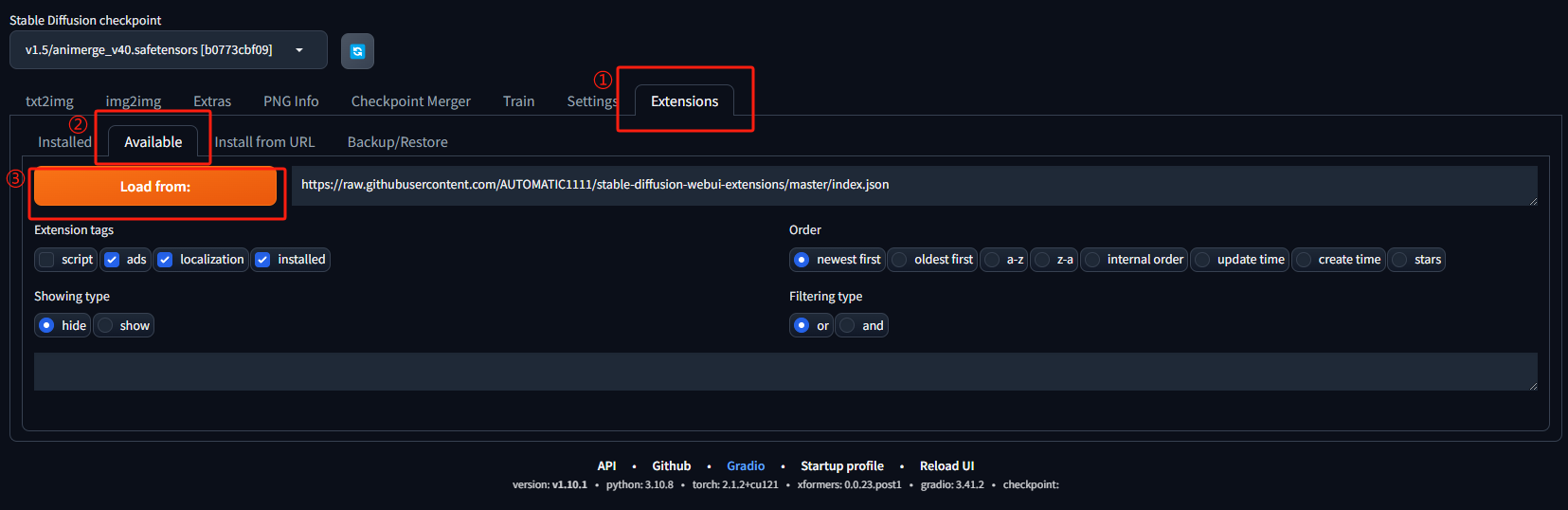
3. 在搜索框输入想要安装的插件,然后点击插件后面的安装按钮
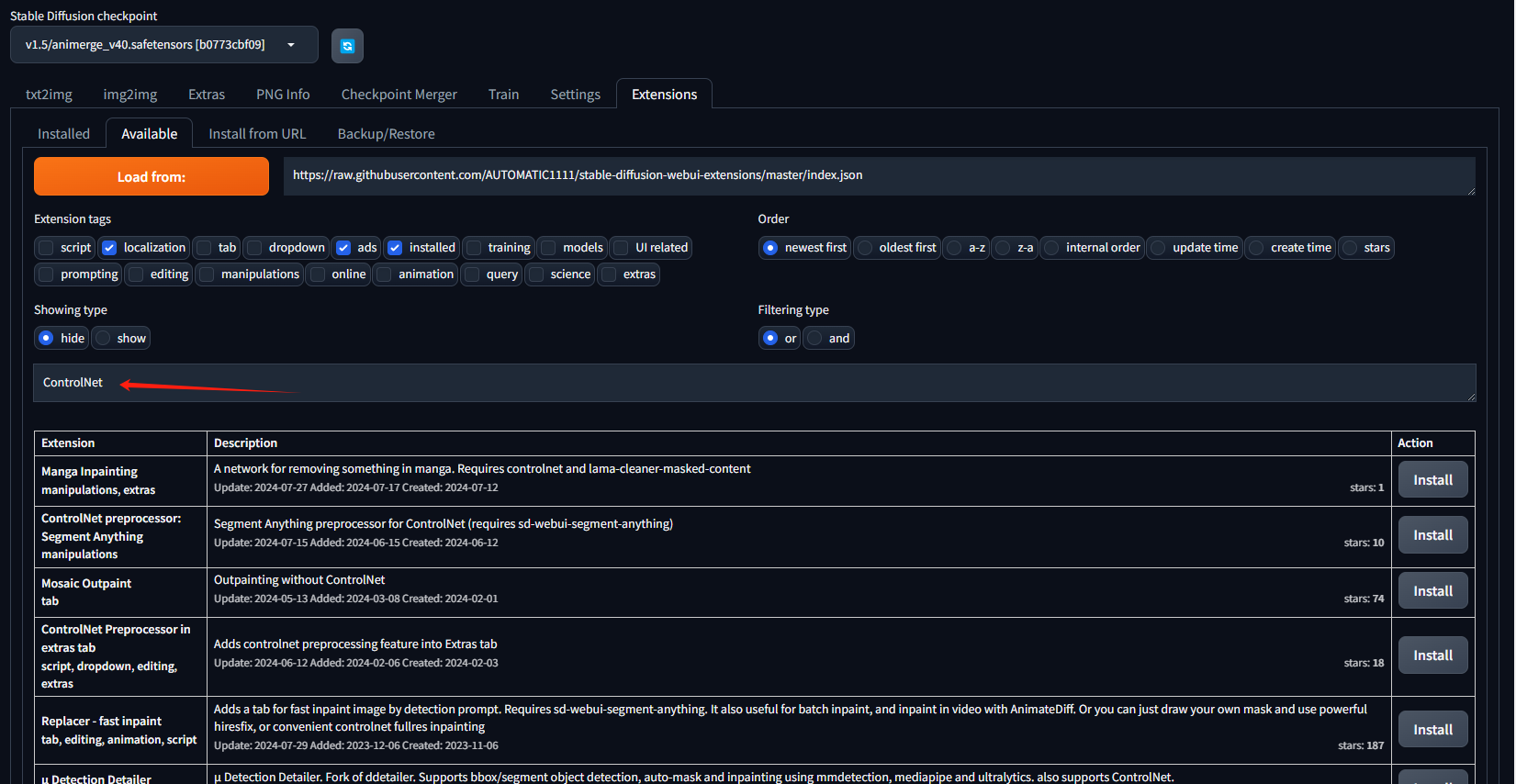
4. 如果你需要的插件不在搜索列表里,可以通过网址进行安装,在git仓库网址输入框中输入你的插件地址,然后点击安装即可。
5. 安装完成后,重启webUI即可。
Stable Diffusion模型介绍
在Stable diffusion中,模型主要分为五大类,分别是Stable diffusion模型、VAE模型、Lora模型、Embedding模型以及Hypernetwork模型。
Stable diffusion大模型( Checkpoint)
Checkpoint 模型,又称 Ckpt 模型或大模型,俗称“底模”,一般模型大小在2GB以上,后缀是.ckpt 和 .safetensors。
使用 Checkpoint 模型的方法也很简单,我们下载好模型文件后,将其存放到 Stable Diffusion 安装目录下\models\Stable-diffusion 文件夹中。如果你是在 WebUI 打开的情况下添加的新模型,需要点击右侧的刷新按钮进行加载,这样就能选择新置入的模型了。
VAE模型
VAE全称Variational autoenconder,中文叫变分自编码器,这种模型可以简单理解为起到一个滤镜的效果。在生成图片的过程中,主要影响的是图片的颜色效果。
一般来讲,在生成图片时,如果没有外挂VAE模型,生成的图片整体颜色会比较暗淡;而外挂了VAE模型的图片整体颜色会比较明亮。
VAE 模型的放置位置是在\models\VAE,因为是辅助 Checkpoint 大模型来使用,所以可以将大模型对应的 VAE 修改为同样的名字,然后在选项里勾选自动,这样在切换 Checkpoint 模型时 VAE 就会自动跟随变换了。
LoRA模型
LoRA(Low-Rank Adaptation Models,低秩适应模型)最初并非针对 AI 绘画领域开发,而是微软研究人员为优化大语言模型的微调过程而提出的技术。
LoRA 模型的文件大小通常在几百 MB,主要是通过设置模型权重或者加上模型触发词来固定目标的特征形象,因此 LoRA 模型在动漫角色还原、画风渲染、场景设计等方面都有广泛应用。
LoRA模型的放在位置在\models\Lora,在实际使用时,我们只需选中希望使用的 LoRA 模型,在提示词中就会自动加上对应的提示词组。
Embeddings
Embeddings模型是最轻量的模型,有的可能只有几十 KB 大小。我们可以将 Embeddings 模型简单理解为封装好的提示词文件。通过将特定目标的描述信息整合到 Embeddings 中,后续只需一小段代码即可调用,效果比手动输入方便快捷得多。例如,平时难以避免的错误画手、脸部变形等问题,都可以通过调用 Embeddings 模型来解决,其中最著名的就是 EasyNegative 模型。
使用方法,只需将下载好的模型放置到 Stable Diffusion 安装目录下\embeddings 文件夹中,使用时点击对应的模型卡片,对应的关键词就会被添加到提示词输入框中,这时再点击生成按钮便会自动启用模型的控图效果了。
Hypernetwork
Hypernetwork可以翻译为“超网络”,它是一种基于神经网络的模型,可以快速生成其他神经网络的参数,常应用于Novel AI的Stable Diffusion模型中。这个模型的作用其实和Lora模型功能有点重叠,使用流程与 LoRA 基本相同。实际应用中,用得比较少。
Stable Diffusion基本参数
- 正向提示词和反向提示词
正向提示词输入框,输入你想要得到得图片描述,反向提示词输入框,输入你不想要画的东西,(注意:提示词框内只能输入英文,所有符号都要使用英文半角,词语之间需要使用英文逗号隔开)
- 一般越靠前的词汇权重越高
- 多数情况下,提示词的格式是:质量词,媒介词,主体,主体描述,背景,背景描述,艺术风格
例子:
best quality,1girl,stand,pink dress,wall background,full of flowers,
一个穿着粉色连衣裙的女孩站在铺满鲜花的墙前
- 调整权重,可以通过语法来对关键词设置权重,一般权重设置在0.5~2之间,可以通过选中词汇,按ctrl+⬆⬇来快速调整权重,每次进步为0.1
例子:(best quality:1.5)
- 词条组合,词条组合的方式跟自然语言差不多,要用介词,比如and,with,of等。
例子:(chair with backrest and armrests)
2. 采样方法
Stable Diffusion中提供了19种采样方法(Sampler)可以选择,Euler a, Euler, LMS, Heun, DPM2, DPM2 a, DPM++ 2S a, DPM++ 2M, DPM++ SDE, DPM fast, DPM adaptive, LMS Karras, DPM2 Karras, DPM2 a Karras, DPM++ 2S a Karras, DPM++ 2M Karras, DPM++ SDE Karras, DDIM, PLMS。以下时常用的:
- 最常用的是Euler a,这是速度最快的采样方式,对采样步数要求比较低,同时随着采样步数增加并不会增加细节,会在采样步数增加到一定步数时构图突变,所以不要在高步数下使用。
- DPM++ SDE Karras / DPM++ 2M SDE Karras,相对于Euler a来说,同等分辨率下细节会更多。
- DDIM,超高步数可以使用,随着步数增加可以叠加细节效果。
3. 采样步数
一般采样步数设置为20~30之间即可
4. 输出分辨率(图片的宽度和高度)
图片的分辨率直接决定了你生成的图片的构成和细节质量。
- 512*512,半身为主
- 768*768,单人全身、站立或者躺坐
- 1024*1024 ,站立为主
5. 随机种子
其它参数不变,同一个随机种子生成的图是相同的,可以通过固定随机种子来锁定图片的风格或者观察各种参数对画图的影响。
6. 提示词相关性CFG
一般CFG越低,画面越素,细节相对较少,CFG越高,画面越仔细,细节较多。
- 二次元风格的CFG可以调高一点,一般在7~12
- 写实风格的CFG比较低,一般4~7
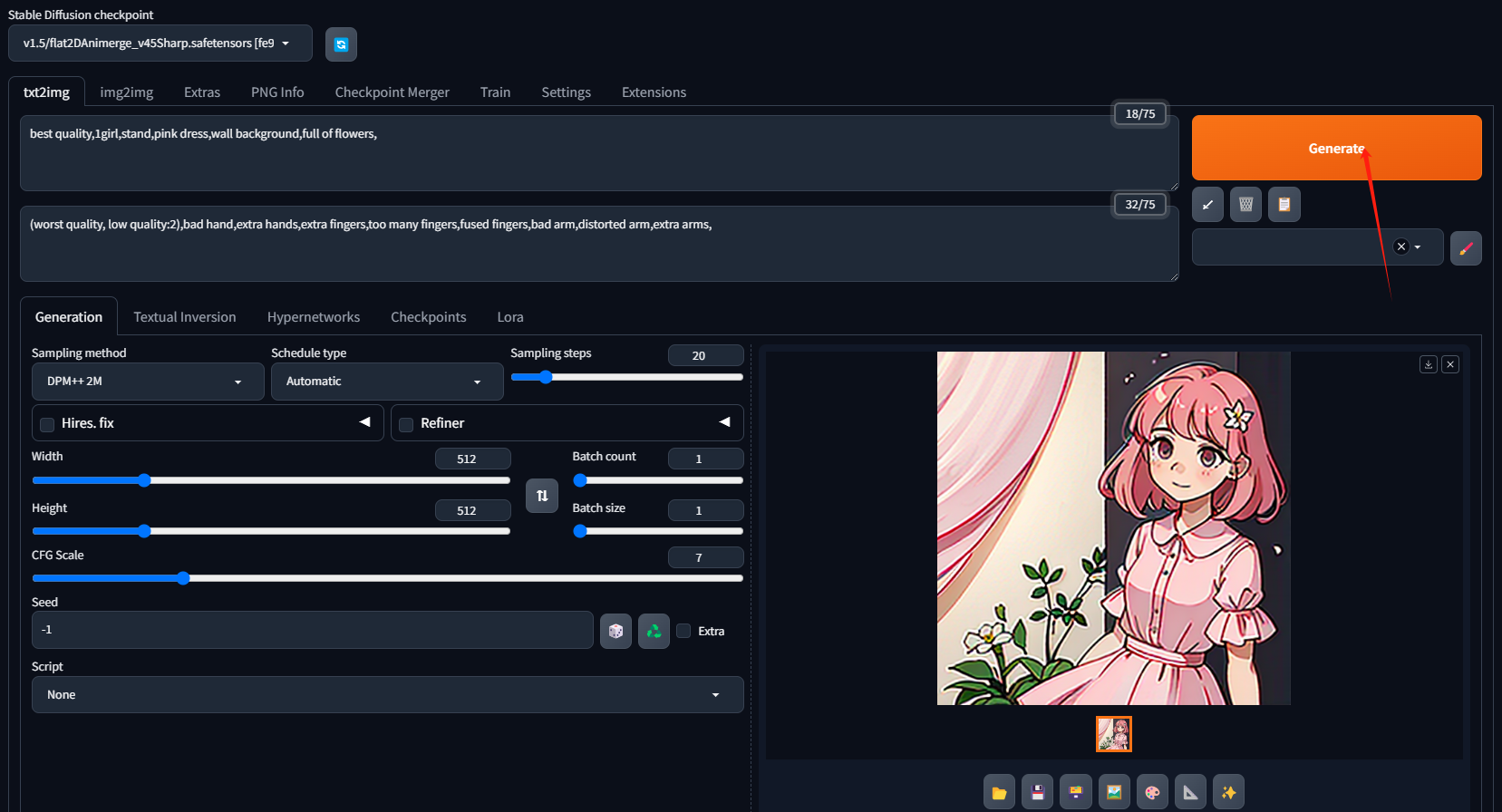
Stable Diffusion文生图
以下是文生图的基本步骤:
- 第一步:打开应用,进入到应用
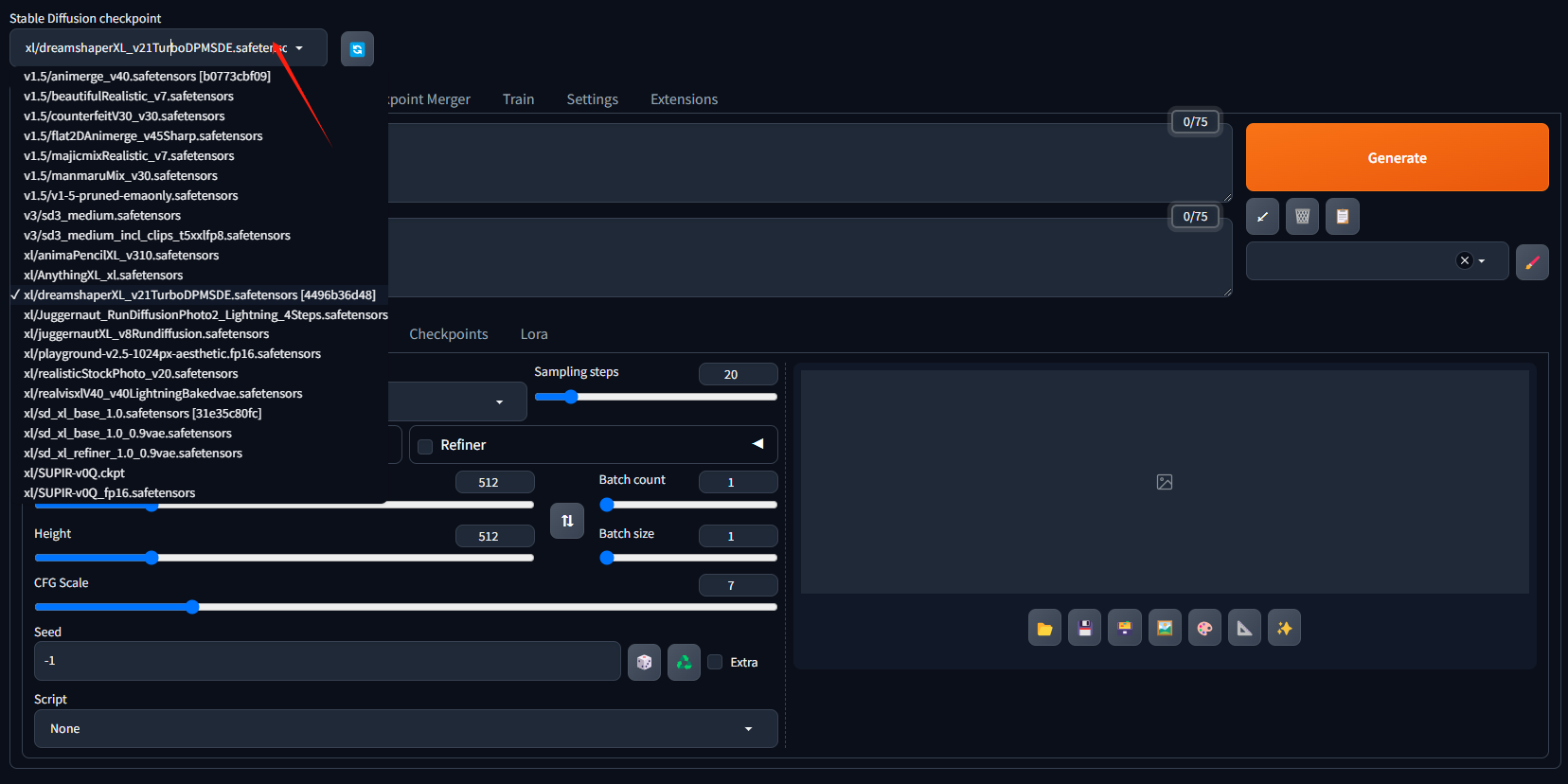
- 第二步:选择一个大模型Checkpoint
这里面已经预置了一部分的模型,如果没有你需要的模型可以自己上传。
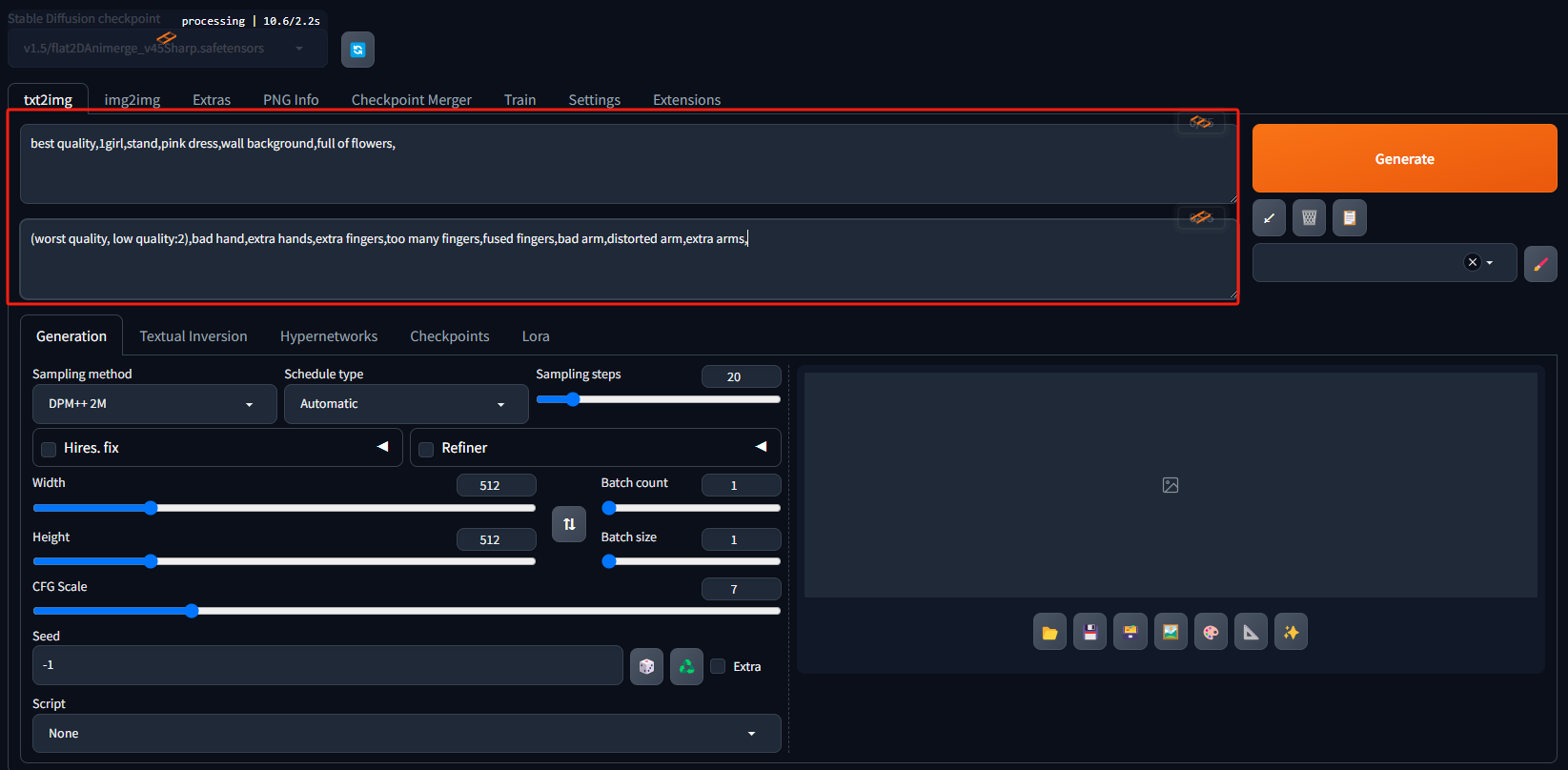
3. 第三步:输入正向提示词和反向提示词正向提示词:best quality,1girl,stand,pink dress,wall background,full of flowers,反向提示词:(worst quality, low quality:2),bad hand,extra hands,extra fingers,too many fingers,fused fingers,bad arm,distorted arm,extra arms,
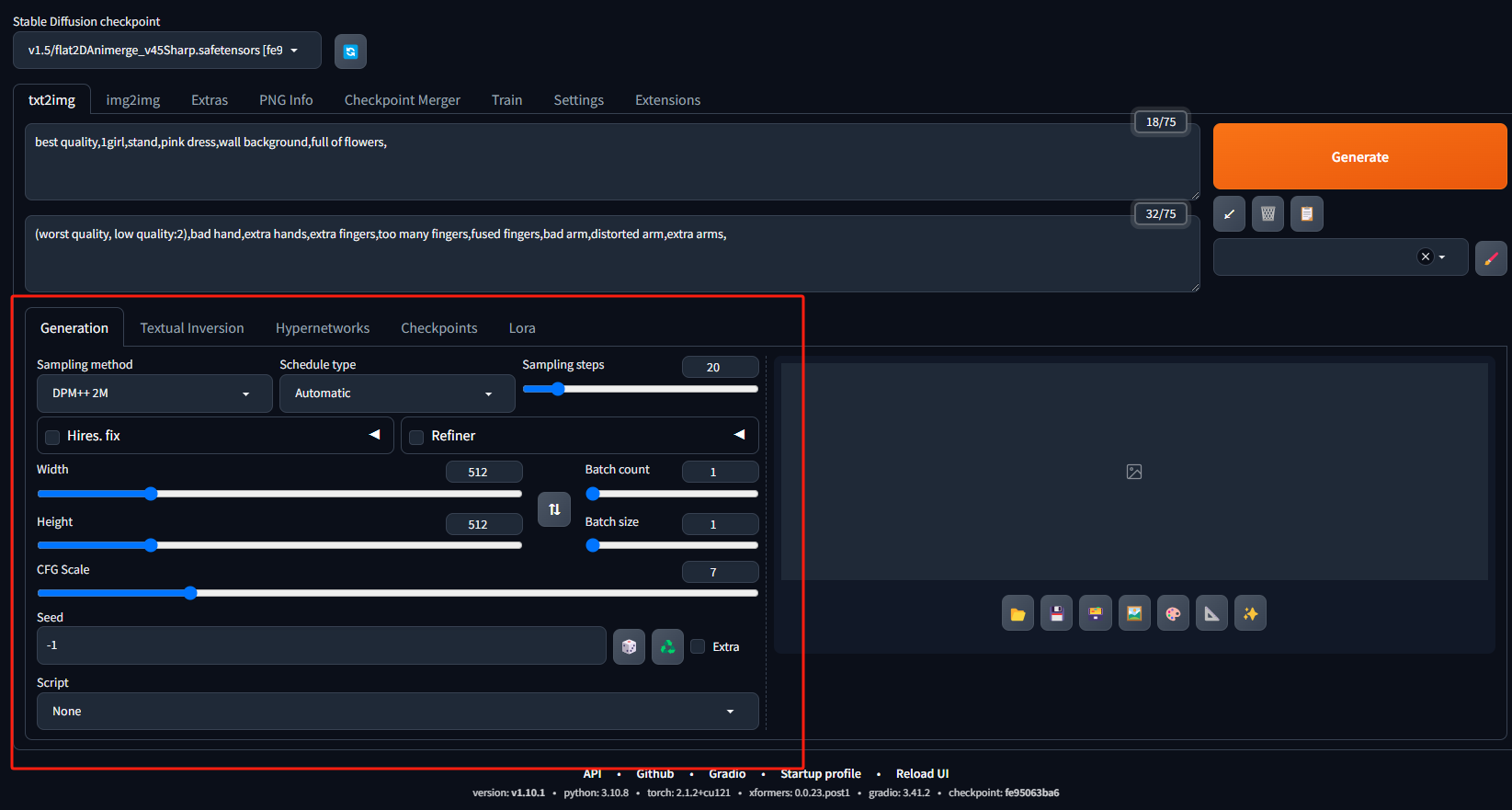
4. 第四步:调整各项参数
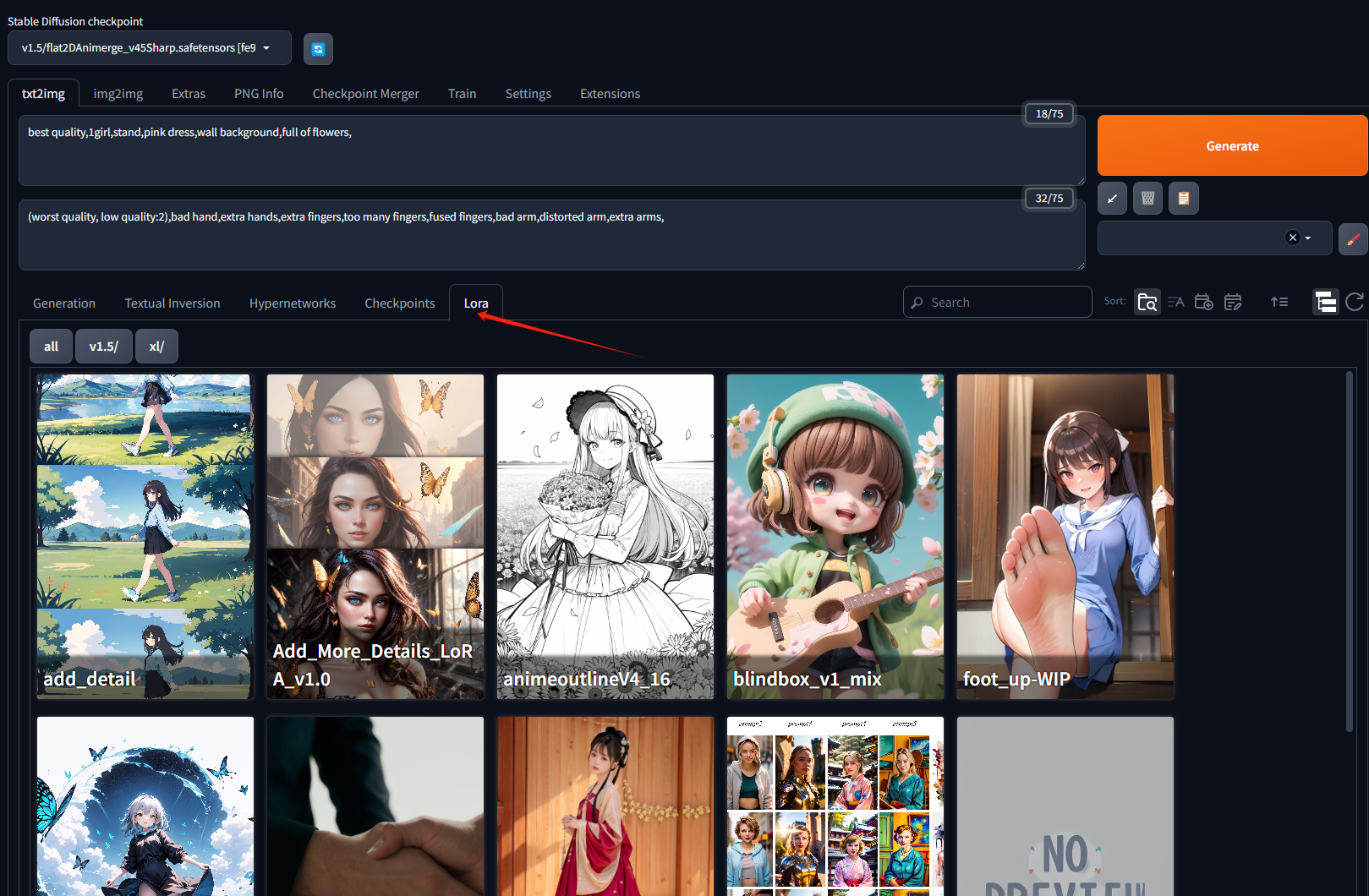
5. 第五步:可以选择一个你想要的风格模型LoRA
6. 点击生成
结语
祝您在猫目平台上创作愉快!这将是给我们的最大的鼓励。