Flux.1迎来全新优化CLIP-L模型:提升图像生成新高度

随着人工智能技术的飞速发展,文本到图像生成领域迎来了新的突破。
由前Stability AI核心团队成员打造的Flux.1模型因其媲美Midjourney的高质量图像输出而备受瞩目。
与Stable Diffusion 3类似,Flux.1在运行时需要搭配CLIP模型,而CLIP模型的性能直接影响最终图像的生成效果。
近日,一款专为Flux.1优化的全新CLIP-L模型——CLIP-GmP-ViT-L-14正式发布,为用户带来了更出色的生成体验。


全新CLIP-L模型:专为Flux.1打造
9月5日,AI社区开发者zer0int在Hugging Face平台发布了优化版CLIP-L模型(项目地址:https://huggingface.co/zer0int/CLIP-GmP-ViT-L-14/tree/main)。
这款模型经过针对Flux.1的特别微调,显著提升了文本指令的遵从度和图像细节的精准度。过去三个月中,zer0int推出了三类CLIP-L优化模型:
- GmP模型:专注于通用优化,发布于今年3月前。
- SMOOTH模型:适合无文字的图像生成,强化细节表现。
- TEXT模型:支持含文字的图像生成,进一步优化细节,最新发布于9月5日,专为Flux.1设计。
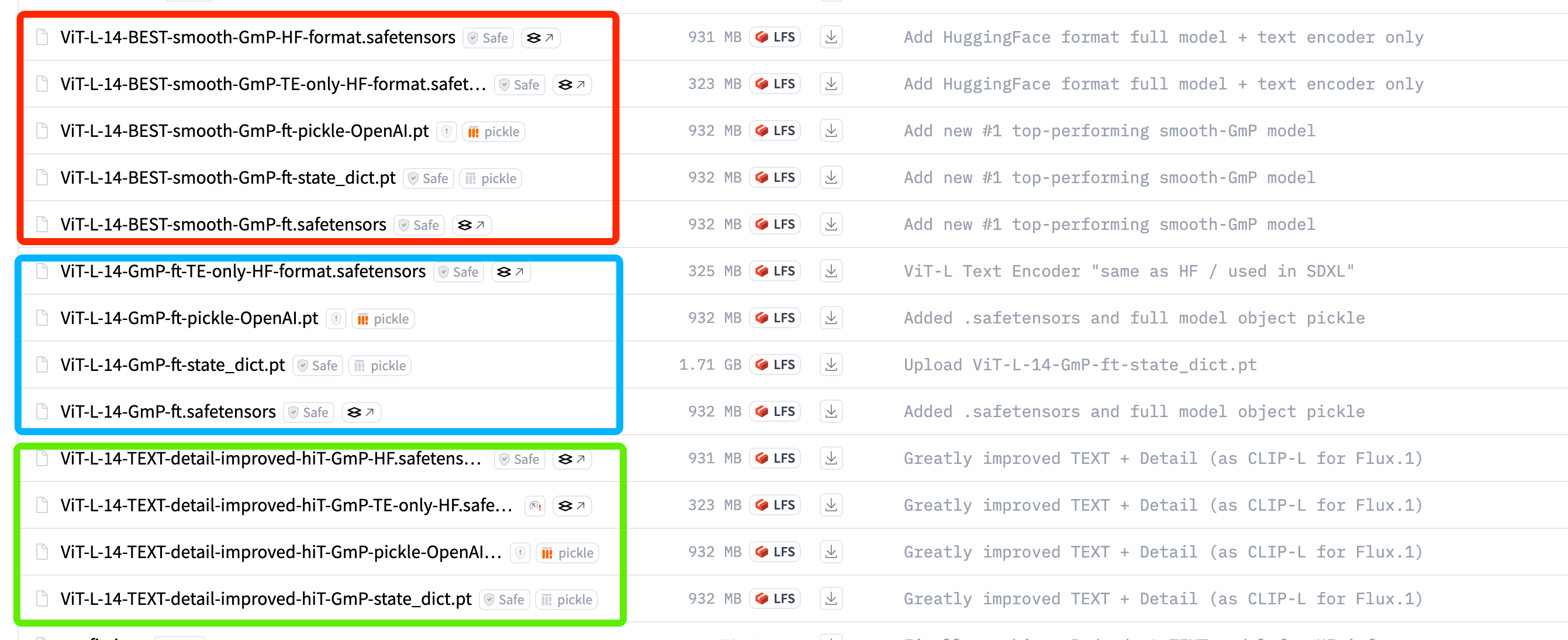
新款CLIP-GmP-ViT-L-14(TEXT模型)可直接替换OpenAI原版的CLIP-L模型,兼容Flux.1及其他主流文本到图像生成工具,为用户提供更高质量的生成结果。
如何在ComfyUI中使用新模型
将这款优化模型融入你的工作流程非常简单,以下是在ComfyUI中的使用步骤:
-
访问Hugging Face页面(https://huggingface.co/zer0int/CLIP-GmP-ViT-L-14/tree/main),下载`ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors`文件。该文件仅包含文本编码器,适合文本到图像生成任务。
-
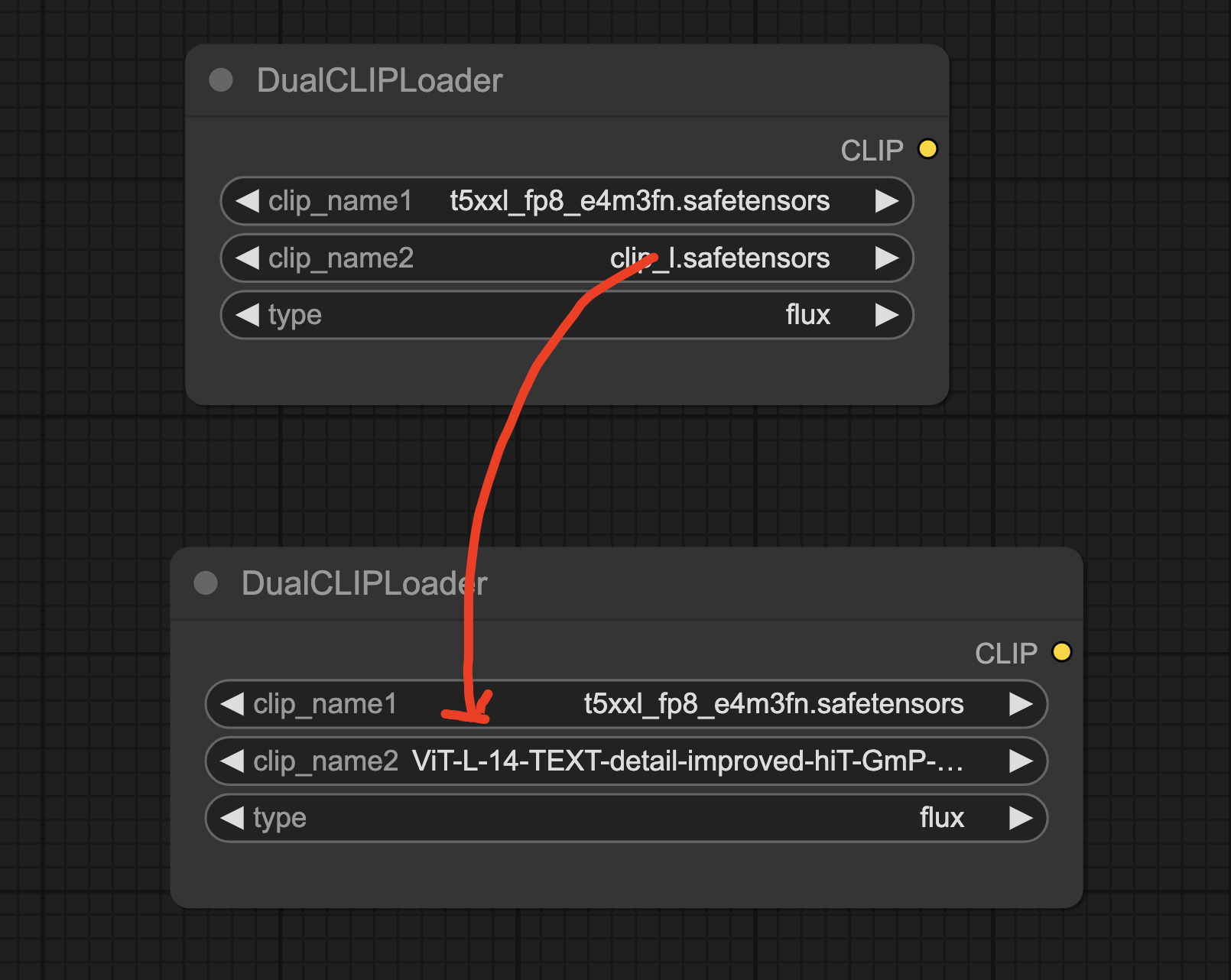
将下载的模型文件放入ComfyUI的
models/clip目录下。 -
在ComfyUI的CLIP节点中,选择
ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors作为CLIP模型。
如下图所示:将原来的CLIP-L模型替换为ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors 这个模型即可。
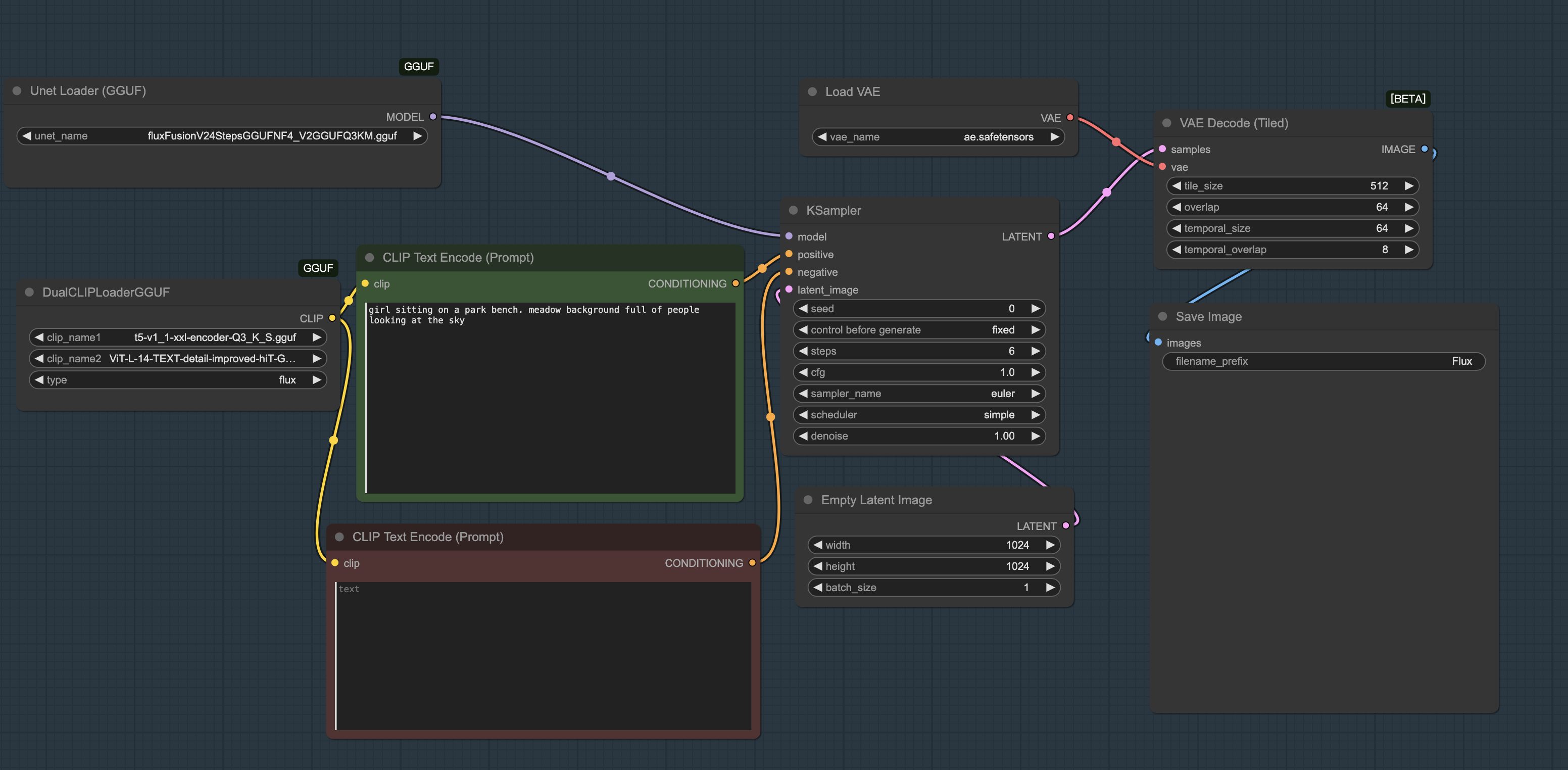
完成以上步骤后,你即可体验到优化后的CLIP-L模型带来的提升。此外,测试显示该模型在GGUF量化环境中也能高效运行,仅需4步即可输出高品质图像。
技术亮点:微调背后的秘密
据zer0int介绍,这款模型的微调基于GmP技术,结合标签平滑(label-smoothing)方法,未更改核心代码。微调过程中,开发者将对比损失函数(ContrastiveLoss)的温度参数从CLIP预训练的0.07调整至较高的0.1,同时优化了其他超参数。这些调整让模型在处理文本指令时更精准,尤其在细节表现上更胜一筹。
CLIP-L与LongCLIP:如何选择?
zer0int还开发了一款LongCLIP模型(项目地址:https://huggingface.co/zer0int/LongCLIP-GmP-ViT-L-14),专为处理复杂场景和长文本提示设计。那么,CLIP-L和LongCLIP该如何选择?
- CLIP-L:输入限制为77个token,有效注意力约为20个token(约15-25个单词)。它在短提示和文本密集任务中表现优异,尤其适合需要高细节准确性的场景。
- LongCLIP:支持更长的提示(嵌入插值至248个token),适合描述复杂场景,例如包含多种元素的自然景观。然而,其细节准确性目前略逊于CLIP-L,且需要特定节点支持,暂无法直接作为标准CLIP-L的替代品。
zer0int建议,对于短提示或需要精确文本渲染的场景,优先选择CLIP-L;若提示内容较长且场景复杂,LongCLIP可能是更好的选择。未来,LongCLIP有望通过更多训练数据(如短、中、长标题的混合数据集)进一步提升性能。
若想在SD1.5、SDXL或Flux.1中使用LongCLIP,可参考SeaArtLab的ComfyUI-Long-CLIP插件(https://github.com/SeaArtLab/ComfyUI-Long-CLIP)。安装该插件后,即可在多种工作流中无缝切换LongCLIP模型。
兼容性与应用场景
新款CLIP-GmP-ViT-L-14模型与SD1.5、SDXL、SD3及Flux.1高度兼容,无需额外调整即可融入现有工作流。无论是生成艺术插图、设计海报,还是打造带文字的商业图像,这款模型都能显著提升输出质量。
例如,在Flux.1中,优化后的CLIP-L能更准确地捕捉提示中的细节,确保图像元素与用户描述高度一致;在SDXL中,它则能提升文字渲染的清晰度和整体画面的质感。
常见问题解答
Q:ViT-L-14-TEXT-detail-improved-hiT-GmP-HF.safetensors和ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors有什么区别?
较小的ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors文件仅包含文本编码器,是文本到图像生成所需的全部内容。
较大的ViT-L-14-TEXT-detail-improved-hiT-GmP-HF.safetensors文件则包含文本编码器和视觉变换器,适用于其他任务,但在生成AI中并非必需。
Q: 如何在文本到图像工作流中使用这款CLIP-L更新?
只需下载ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors文件,将其放入你的模型文件夹(如ComfyUI/models/clip),然后在CLIP加载器中选择它即可。操作简单,轻松上手!
Q: 这款CLIP-L更新能与我现有的Stable Diffusion或Flux模型兼容吗?
完全可以!这款CLIP-L更新与SD 1.5、SDXL、SD3和Flux兼容。这些模型默认使用标准CLIP-L,因此你可以无缝地将这款优化版本融入你的工作流。
总结
CLIP-GmP-ViT-L-14的发布为Flux.1用户带来了全新的创作可能。通过精细的微调和强大的兼容性,这款CLIP-L优化模型不仅提升了图像生成的细节表现,还让用户能够更轻松地实现创意想法。无论你是AI艺术创作者还是技术开发者,这款工具都值得一试。





