Claude Opus 4.7 来了:看得更清楚了,但用起来也更“费”了

今年 Anthropic 又一次把行业节奏带飞了。
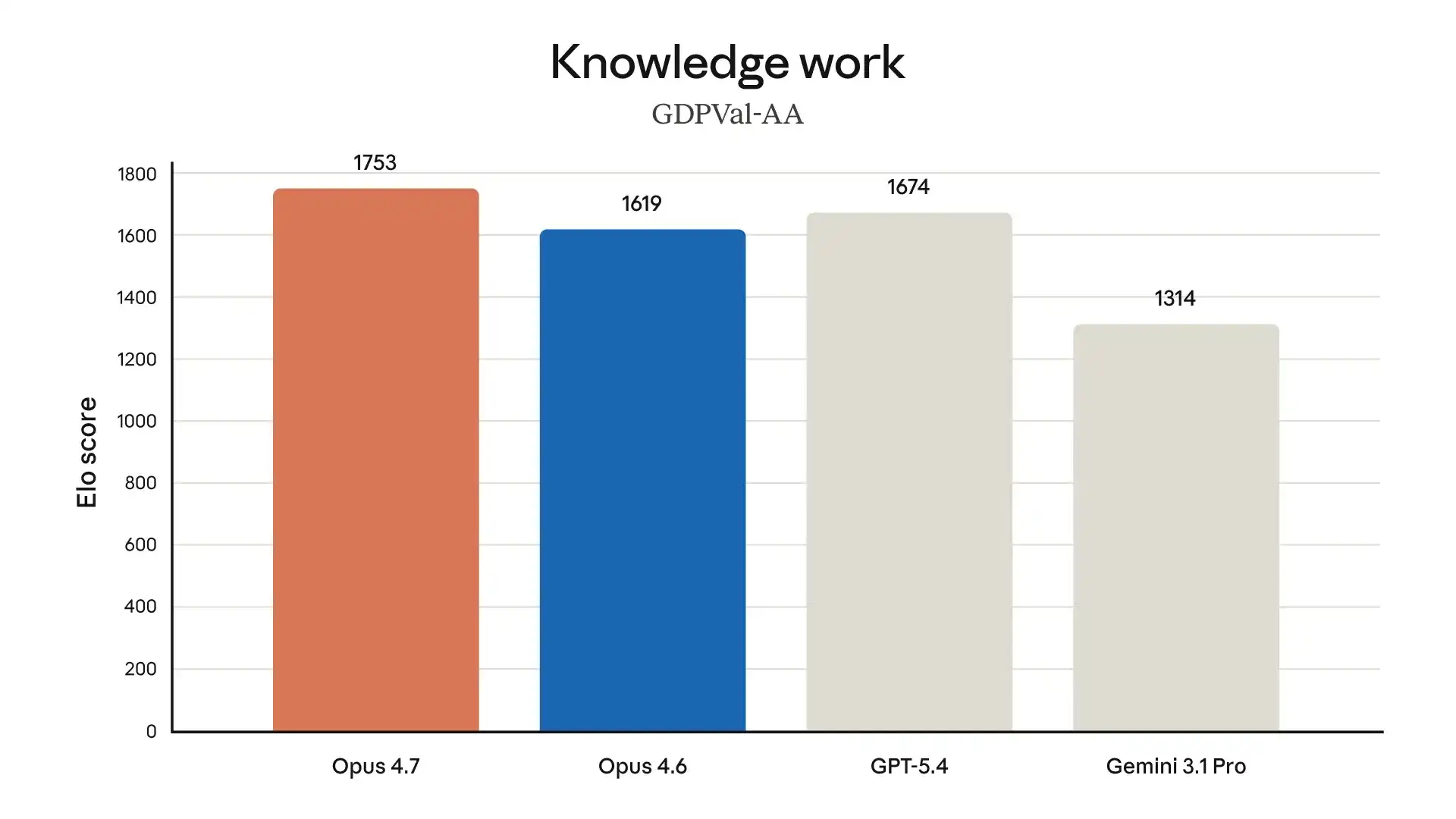
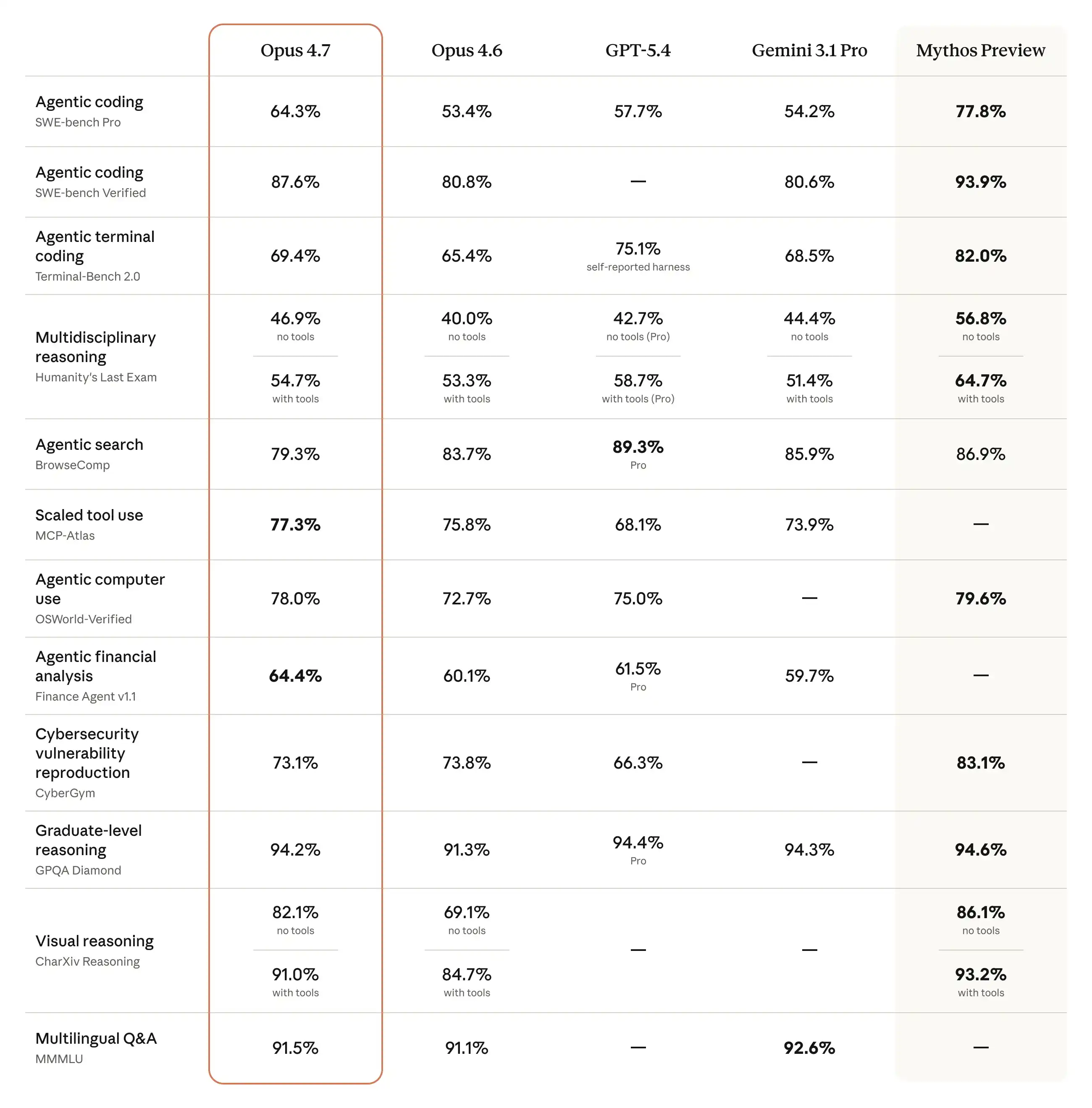
Claude Opus 4.7 正式上线,朋友圈和 X 平台瞬间被刷屏,各种基准截图和「这下真卷不动了」的感慨铺天盖地。但真正值得关注的,不是那些大家都在转的表面数字,而是三个大部分报道都没说透的东西:视觉能力的巨大飞跃、让人又爱又恨的自适应思考模式,以及那个藏在「价格不变」背后的真实使用成本。
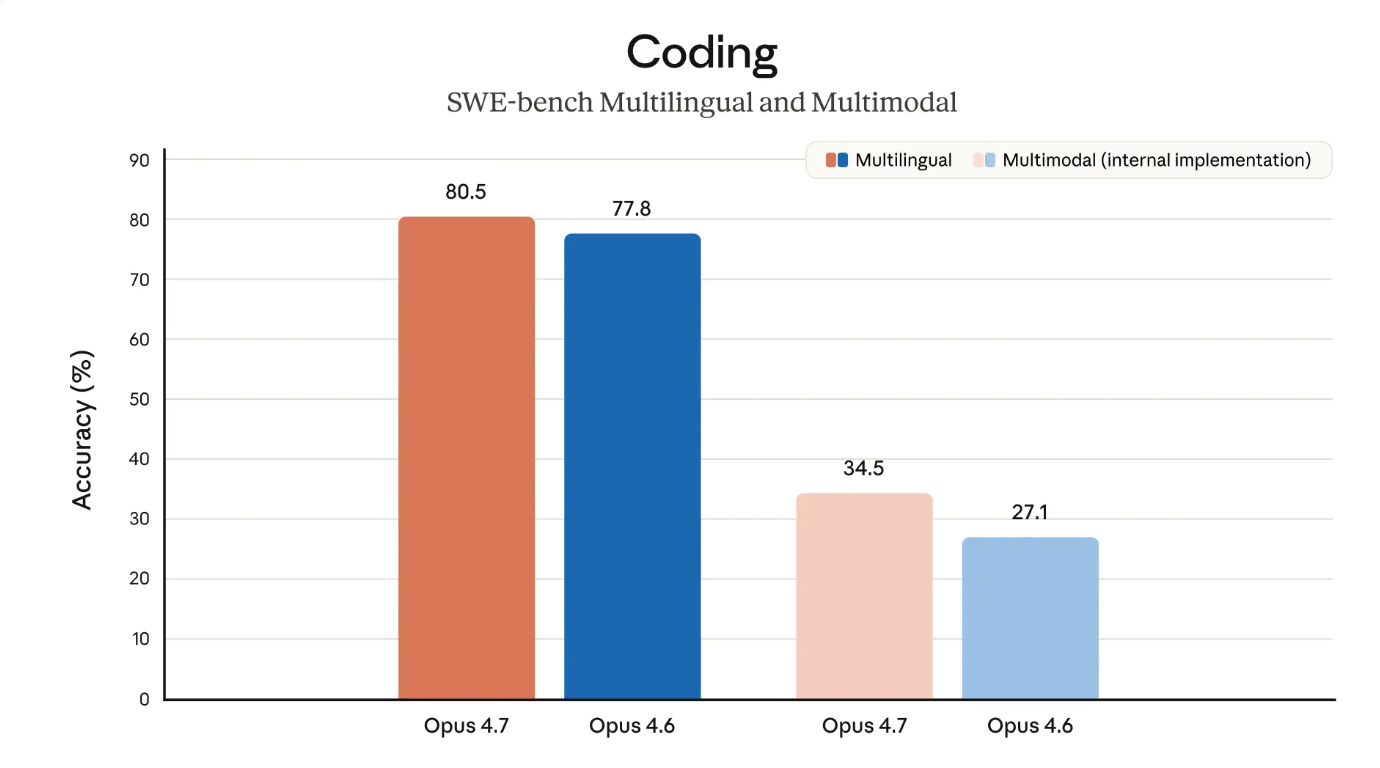
过去 Claude 在写代码这件事上一直很强,但只要一涉及到「看懂自己写的东西」,体验就直接崩盘。给你生成的界面截图,它经常像隔着老式监控摄像头看东西,要么漏掉明显问题,要么脑补出根本不存在的元素。
Opus 4.7 把这个痛点狠狠补上了。
视觉推理基准 CharXiv 从 69.1% 直接跳到 82.1%,这是本次发布里单项提升最夸张的成绩。核心变化是它现在能处理长边高达 2576 像素的图像,分辨率直接是之前的 3 倍以上,不再强制降采样。
实际体验提升非常明显:贴一张 App 截图问「这个按钮为什么错位」,它能精准看到 padding、字体粗细、对齐偏差这些细节;处理财务报表、多图表工程图时,也能真正读出具体数值;做界面调试、幻灯片排版、文档美化时,细节品味明显上了一个台阶。
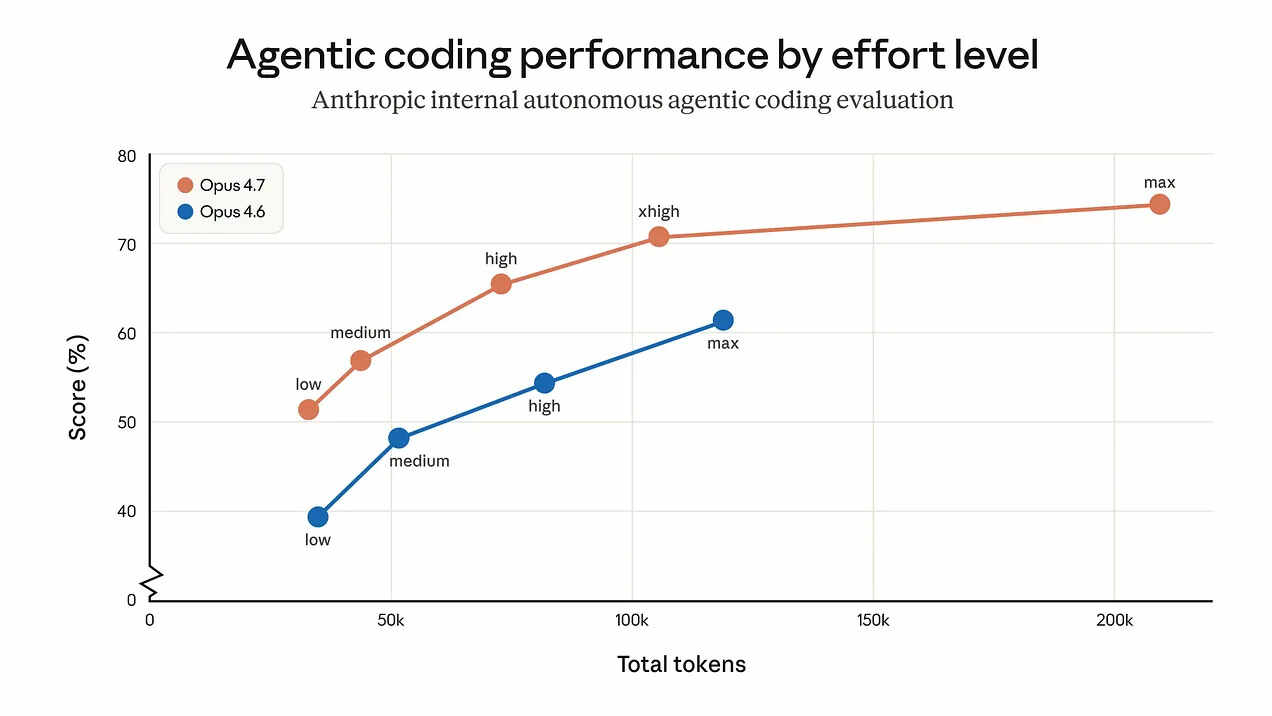
这次最大的机制变化,是思考模式的彻底重构。以前你可以手动开关「总是扩展思考」,现在 Opus 4.7 默认进入自适应思考:简单问题就快速回答,复杂问题自动深度思考。你无法彻底关闭它,只能通过新的 effort 级别来调节(新增了 xhigh 档位,位于 high 和 max 之间)。
Claude Code 里,4.7 的默认 effort 直接拉到 xhigh。这意味着它在大多数任务上会「多想一会儿」,输出质量更高,但 Token 消耗也明显增加。
官方定价完全没动,依然是输入 5 / 输出 25 per million tokens。但 Anthropic 自己的文档里写得很清楚:新分词器让相同文本的 Token 数量最多增加 35%。再叠加自适应思考和 xhigh 默认设置,实际使用成本大概率会上涨 10-25%。
Pro 和 Max 用户尤其需要注意:你的周限额是按 Token 计算的。现在同样的任务消耗更多 Token,意味着你会比以前更快触达上限。已经有用户反馈,上线当天就差点把周额度干穿。
除了视觉和思考模式,其他提升也值得关注:指令跟随变得更严格,老 Prompt 可能出现意外结果;提示注入防御大幅增强;新增 /ultrareview 命令,能像资深 Reviewer 一样深度检查代码;Auto Mode 扩展到 Max 用户,长任务运行更丝滑;在真实职业场景测试中,它也表现得更像一个「能干活的同事」。
当然也有退步,某些 Agentic Search 和网络安全相关能力被主动压制,这是 Anthropic 一贯的安全策略,为 Mythos Preview 做准备。
到底值不值得切换?如果你是重度视觉和界面工作用户,这次升级能真正改变生产力;如果你主要写代码且对成本敏感,建议先小范围测试,把 effort 调到 high 或 medium 观察实际消耗;Claude Code 重度用户值得升级,但一定要学会调参数。
至于那个还在藏着的 Claude Mythos Preview,Anthropic 依然不慌不忙。Opus 4.7 更像是他们在 Mythos 完全准备好之前,交出的一份「可用性优先」的答卷。
Opus 4.7 不是那种炸裂式的降维打击,而是把「好用」这件事又往前推了一大步。它看得更清楚、想得更深、也更敢负责,但也更「费」。
真正的聪明从来不是无限堆 Token,而是让你用得安心、省心、放心。

comfyUI:Ruyi-Models:将静态图像变为电影级视频
2025年04月11日

SkyReels-A2开源革命:解锁商用级‘元素到视频’的无限创意
2025年04月10日

Flux.1迎来全新优化CLIP-L模型:提升图像生成新高度
2025年04月10日

玩转 Ollama:让大模型在你电脑上“飞”起来!
2025年04月11日

Generative AI for Beginners:微软的开源 AI 入门课,带你从零开始玩转生成式 AI
2025年04月12日

LLMs-from-Scratch:从零打造ChatGPT的开源教科书
2025年04月13日

探秘微软的AI-For-Beginners:零基础也能玩转AI的开源宝藏
2025年04月13日