Open WebUI:打造你的私人AI界面,轻松玩转本地大模型!

如果你是个对AI感兴趣的开发者,或者只是想在本地搞个聊天机器人玩玩,那么今天要介绍的这个开源项目——Open WebUI(原名Ollama WebUI),绝对值得你花几分钟了解一下!它的GitHub地址是:https://github.com/open-webui/open-webui。简单来说,这是一个让你在本地运行AI模型的超级友好界面,支持多种大语言模型(LLM),还能完全离线使用,隐私拉满!下面我们就来聊聊它的功能、技术栈、实现逻辑,以及上手难度,带你快速入门这个开源神器!
一、Open WebUI是什么?能干啥?
Open WebUI 是一个开源的AI交互界面,主要目标是让开发者(甚至普通用户)能轻松地跟本地运行的大语言模型(LLM)互动。想象一下,你在自己电脑上跑了个Llama、Mistral,或者其他开源模型,然后通过一个美观、易用的网页界面跟它聊天、写代码、生成图片,甚至还能处理文档查询——这不就是个私人ChatGPT吗?
核心功能
- 多模型支持:支持Ollama、OpenAI兼容API,以及其他LLM运行框架。你可以用它跟多个模型同时“聊天”,还能让它们协作回答问题。
- 离线运行:完全本地化,数据不上传云端,隐私有保障。适合对数据安全敏感的场景。
- RAG(检索增强生成):内置文档检索功能,上传PDF、Word等文件,模型就能基于这些内容回答问题。写论文、查资料超方便!
- 语音和视频交互:支持语音输入输出,甚至可以视频通话,体验有点像科幻电影里的AI助手。
- 图像生成:集成了Stable Diffusion、DALL-E等图像生成API,想让AI画画?一键搞定!
- 自定义工具:支持Python函数调用,开发者可以自己写工具,让模型干更复杂的事,比如爬网页、分析数据。
- 多语言支持:界面支持多国语言,中文用户用起来毫无障碍。
- 权限管理:有RBAC(基于角色的访问控制),适合团队部署,限制谁能用哪些模型。
应用场景
- 个人学习:想研究大模型但不想花钱买云服务?用Open WebUI本地跑模型,边玩边学。
- 企业内网:公司需要AI但不想数据外泄?部署在本地服务器,员工通过网页访问,安全又高效。
- 开发者工具:写代码、调试模型、测试RAG效果,Open WebUI都能当个好帮手。
- 教育/研究:高校实验室可以用它来教学生AI知识,或者跑实验验证模型性能。
二、技术架构:它是怎么搭起来的?
Open WebUI 的架构设计非常现代化,前后端分离,模块化程度高,扩展性强。下面简单拆解一下它的技术架构:
前端
- 框架:基于React(或类似的前端框架),界面响应式设计,简洁直观。
- 功能模块:聊天窗口、模型选择、文件上传、语音交互等都通过前端组件实现,支持动态渲染。
- WebSocket:实时通信用WebSocket,保证聊天、语音等功能流畅无延迟。
后端
- 核心语言:Python,代码清晰,社区友好。
- API层:提供OpenAI兼容的API接口,方便跟Ollama或其他LLM框架对接。
- RAG引擎:内置检索增强生成模块,基于向量数据库(可能是Chroma或FAISS)存储文档嵌入。
- 数据库:用SQLite或Redis存储用户数据、聊天记录,部署简单。
- 推理支持:通过Ollama或其他推理框架调用本地模型,GPU加速可选(需要NVIDIA CUDA)。
部署
- Docker:官方推荐Docker部署,一条命令拉镜像跑服务,省心省力。
- Kubernetes/Helm:支持集群部署,适合大规模企业场景。
- 本地安装:也支持直接用pip安装,Python 3.11环境即可。
整体来看,Open WebUI 的架构就像一个“AI中台”,前端负责用户体验,后端负责模型调度和数据处理,中间通过API和WebSocket桥接,扩展性极强。
三、核心模块实现逻辑:怎么让AI这么聪明?
Open WebUI 的几个核心功能背后,藏着一些有趣的实现逻辑。我们挑几个重点看看:
1. 多模型对话
- 逻辑:用户选择多个模型(比如Llama和Mistral),前端发送请求到后端,后端通过API并行调用每个模型的推理接口。结果汇总后按顺序展示,或者让模型“讨论”出最佳答案。
- 实现:后端用异步框架(可能是FastAPI)处理并发请求,模型推理通过Ollama的本地服务完成。
- 亮点:支持模型间“协作”,有点像AI版的“头脑风暴”。
2. RAG(检索增强生成)
- 逻辑:用户上传文档后,后端把文档切分成小块(chunk),用嵌入模型(比如BERT或SentenceTransformer)生成向量,存进向量数据库。查询时,先检索相关片段,再喂给LLM生成答案。
- 实现:可能用LangChain或LlamaIndex做RAG pipeline,查询效率高,答案更精准。
- 亮点:本地RAG无需联网,适合处理敏感文档。
3. 语音交互
- 逻辑:前端用WebRTC捕获语音,发送到后端转成文本(STT,语音转文本),LLM处理后生成回复,再通过TTS(文本转语音)返回音频。
- 实现:可能集成了Whisper(语音识别)和一些开源TTS模型,全部本地跑。
- 亮点:端到端本地化,延迟低,体验接近Siri。
4. 图像生成
- 逻辑:用户输入提示词,后端调用Stable Diffusion或DALL-E的API,生成图片后通过前端展示。
- 实现:支持本地部署AUTOMATIC1111的Stable Diffusion WebUI,或者通过外部API(如OpenAI)。
- 亮点:一张RTX 3060就能跑简单的图像生成,性价比高。
这些模块的实现都依赖高度模块化的设计,开发者可以轻松替换某个部分(比如换个TTS模型),灵活性很强。
四、使用的技术栈:现代又接地气
Open WebUI 的技术栈非常“亲民”,对Python开发者尤其友好。以下是主要技术:
- 前端:React(或Vue,可能有TypeScript),Tailwind CSS(样式),WebSocket。
- 后端:Python 3.11,FastAPI(或Flask),Ollama(模型推理),LangChain/LlamaIndex(RAG)。
- 数据库:SQLite(轻量存储),Redis(缓存,可选),Chroma/FAISS(向量数据库)。
- 部署:Docker,Kubernetes,Helm,NVIDIA CUDA(GPU加速)。
- 其他工具:Whisper(语音识别),Stable Diffusion(图像生成),OpenTelemetry(监控,可选)。
技术栈的选择很务实,既有现代化的框架(FastAPI、React),又有社区成熟的工具(Ollama、LangChain),开发和维护成本都不高。
五、上手难度:新手也能玩得转吗?
Open WebUI 的上手难度可以说是中低水平,对有一定编程基础的人(比如会点Python、了解Docker)来说,部署和使用都不算复杂。
部署难度
- Docker方式(推荐):一条命令(
docker run ...)就能跑起来,十分钟内搞定。官方文档详细,社区活跃,遇到问题搜一下基本能解决。 - 本地安装:需要Python 3.11环境,跑
pip install open-webui安装依赖。如果要用GPU,还得装CUDA,稍微麻烦点。 - 硬件要求:CPU就能跑,但想流畅用大模型(比如13B参数),建议8GB+显存的GPU(RTX 3060起步)。内存至少16GB。
使用难度
- 界面:傻瓜式操作,打开网页就能用,上传文件、选模型、聊天都直观。
- 高级功能:想用RAG、写自定义工具,需要看文档,懂点Python和AI基础会事半功倍。
- 学习曲线:新手可能对Ollama、模型选择有点懵,但跟着官方教程走,1-2小时就能上手。
总的来说,Open WebUI 对初学者友好,官方还提供了Discord社区,随时问问题,体验很不错。
六、跟其他项目的对比:有啥不一样?
Open WebUI 不是唯一一个AI交互界面,我们来跟几个类似项目比比看:
1. vs. text-generation-webui
- 共同点:都支持本地LLM,都有网页界面。
- 不同点:
- Open WebUI 更注重通用性,支持RAG、语音、图像生成,功能更全。
- text-generation-webui 更专注文本生成,适合深度调参,界面略简陋。
- 选择建议:想要“开箱即用”选Open WebUI,想深度研究模型选text-generation-webui。
2. vs. AUTOMATIC1111/stable-diffusion-webui
- 共同点:都是AI的Web界面,支持本地部署。
- 不同点:
- Open WebUI 是通用AI平台,主打LLM交互,顺带支持图像生成。
- AUTOMATIC1111 专注图像生成(Stable Diffusion),对绘画优化更好。
- 选择建议:图像生成需求多选AUTOMATIC1111,综合AI需求选Open WebUI。
3. vs. LangChain UI
- 共同点:都支持RAG和LLM。
- 不同点:
- Open WebUI 是完整的前后端解决方案,界面友好。
- LangChain UI 更像开发框架,界面需要自己搭,灵活性更高。
- 选择建议:不想写前端代码选Open WebUI,想完全定制选LangChain。
总结一句:Open WebUI 的定位是“全能选手”,功能覆盖广,上手简单,适合大多数本地AI场景。
七、总结:为什么值得一试?
Open WebUI 就像一个AI的“瑞士军刀”,不管你是想玩玩本地大模型、做个私人知识库,还是开发企业级AI应用,它都能派上用场。它的优点总结一下:
- 功能丰富:聊天、RAG、语音、图像生成一网打尽。
- 隐私至上:完全离线,数据不外泄。
- 易用性强:Docker部署简单,界面直观。
- 社区活跃:GitHub星数8.8k+,更新频繁,文档完善。
当然,它也有点小不足,比如某些高级功能(像自定义工具)文档不够详细,初学者可能需要多摸索。但瑕不掩瑜,整体体验非常棒!
如果你对AI感兴趣,或者想在本地折腾个ChatGPT替代品,不妨去GitHub clone一下代码,跑起来试试。说不定,你会爱上这个开源小宇宙!😄
动手试试吧! 欢迎在评论区分享你的部署经验,或者告诉我你还想了解哪些AI开源项目~
参考资料:
- Open WebUI 官方文档:https://docs.openwebui.com
- GitHub 仓库:https://github.com/open-webui/open-webui

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
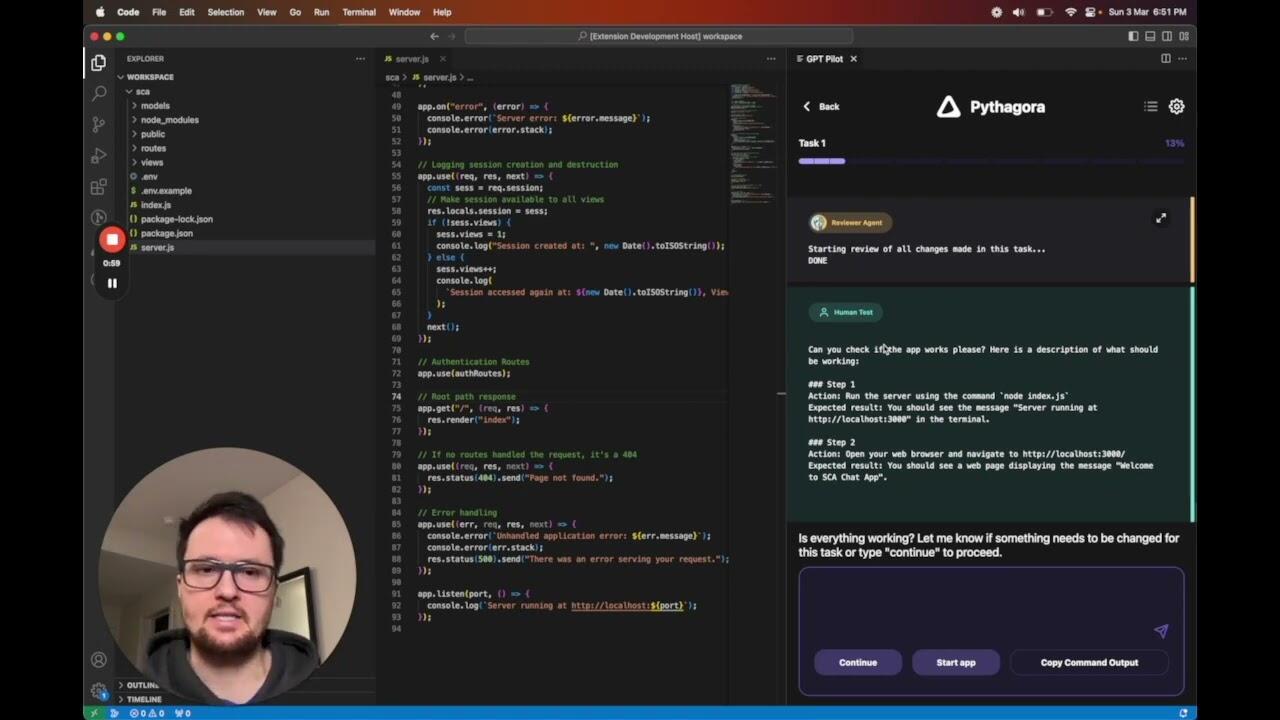
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
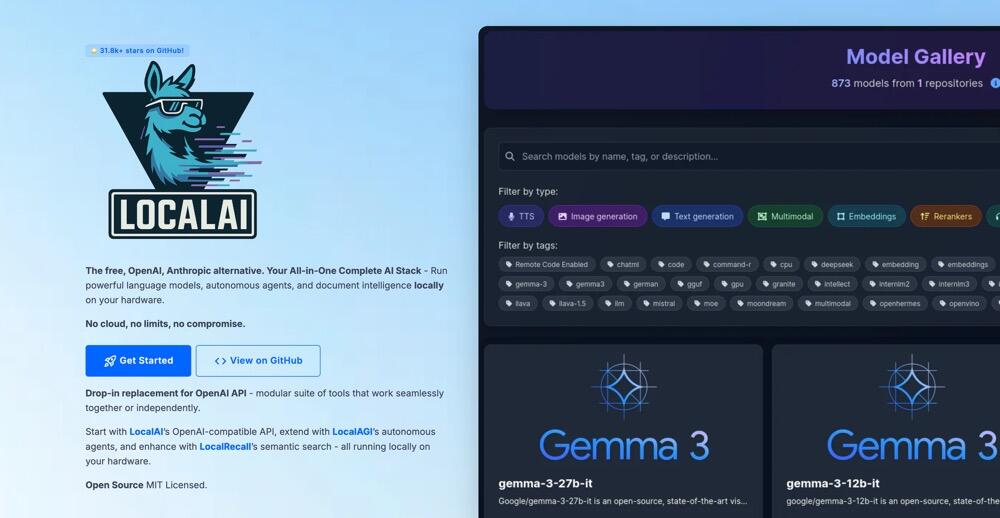
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
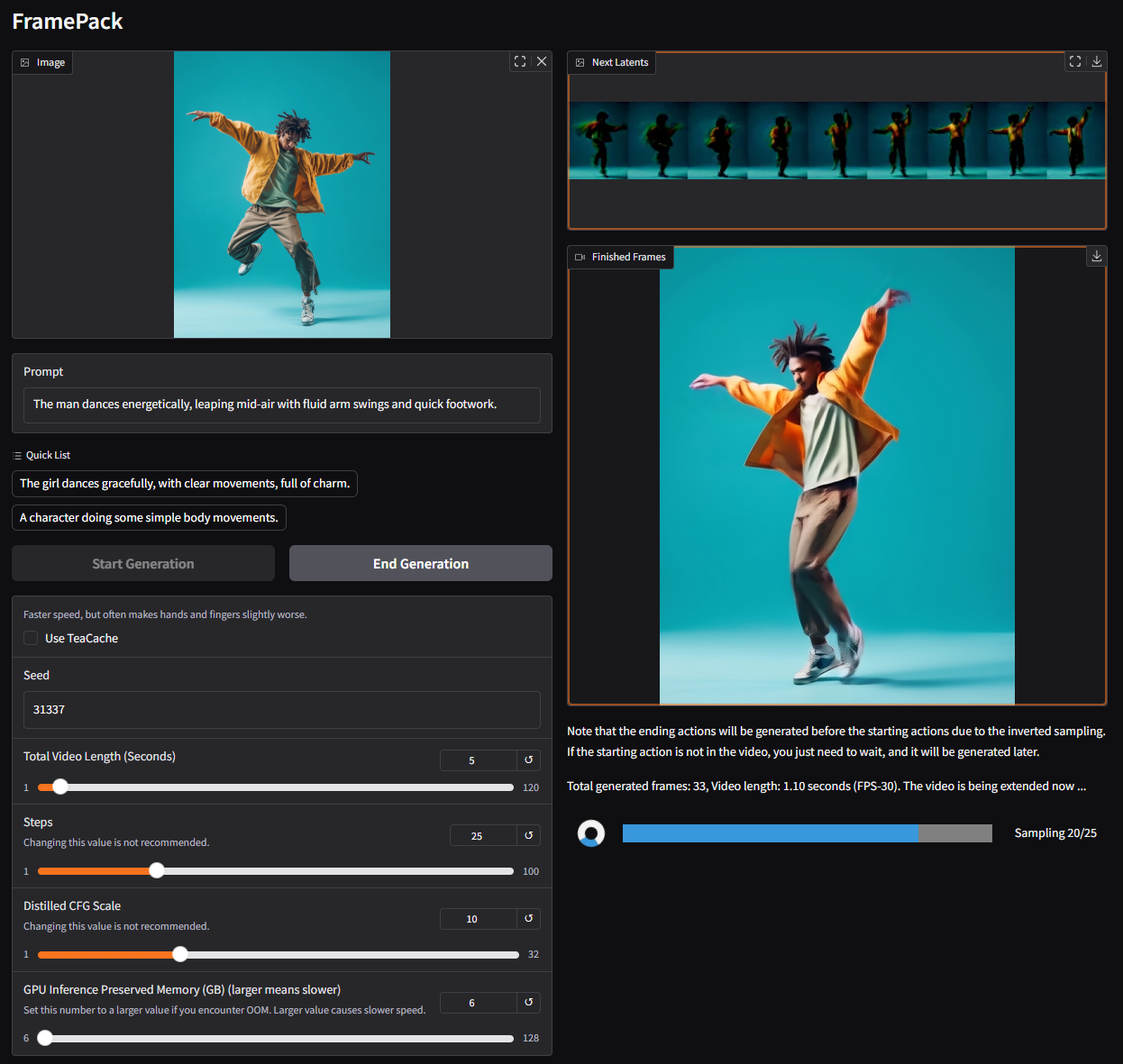
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
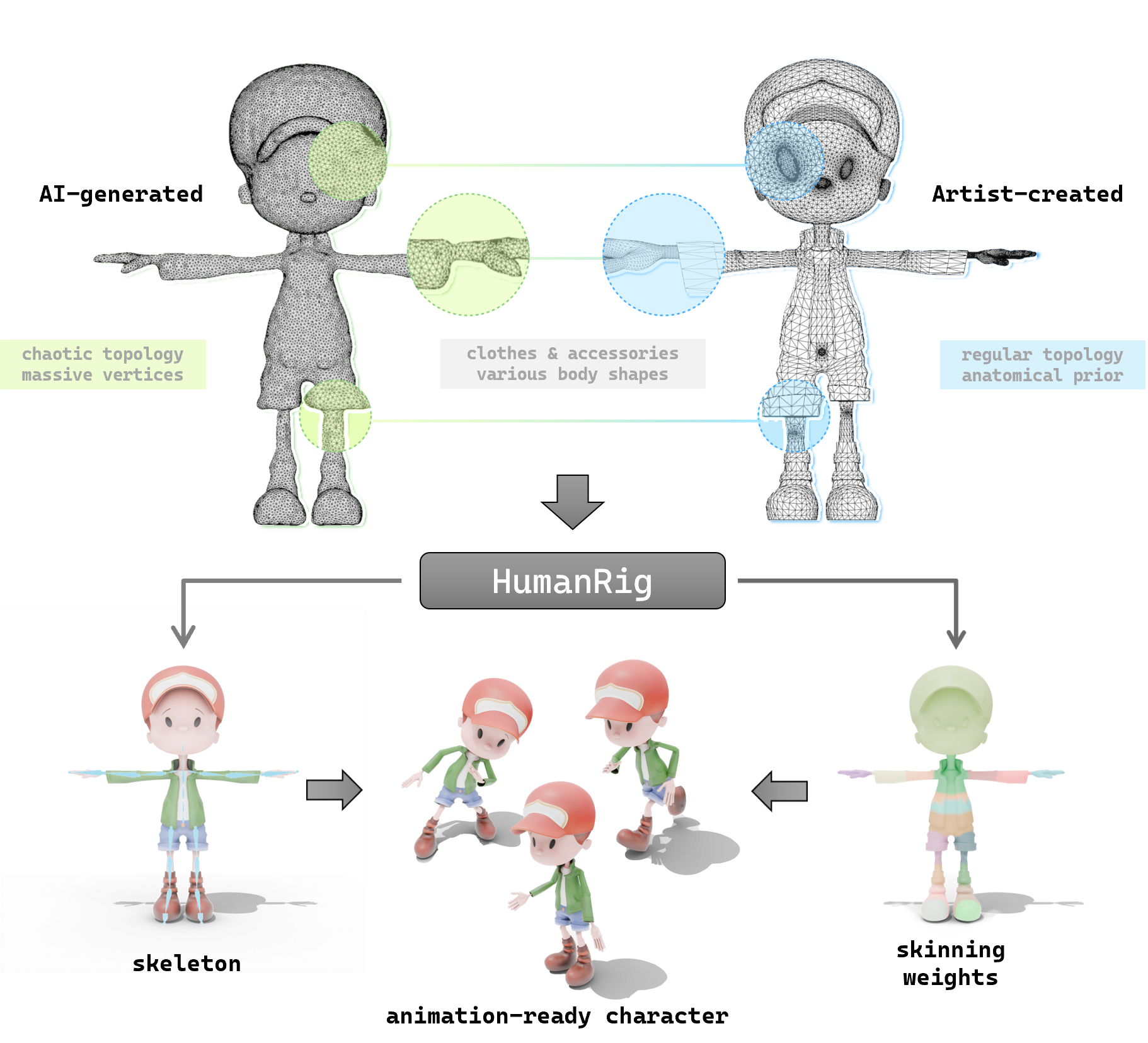
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器
2025年04月22日
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日

让 AI 更懂你的网站:一文读懂 llms-txt 开源项目
2025年04月24日