Quivr:你的AI“第二大脑”,开源RAG框架了解一下!

如果你是个喜欢折腾AI的开发者,或者对如何快速构建一个能“聊”文件的智能助手感兴趣,那么今天要介绍的这个开源项目绝对值得你关注!它就是 Quivr(GitHub地址),一个号称“第二大脑”的开源RAG(Retrieval-Augmented Generation,检索增强生成)框架。接下来,我们以轻松易懂的风格,聊聊 Quivr 的功能、技术架构、核心逻辑、技术栈、上手难度,以及它跟其他项目的对比,带你快速get这个项目的精髓!
一、Quivr 是什么?能干啥?
Quivr 的定位很简单:帮你打造一个AI驱动的个人知识库,像“第二大脑”一样,随时随地聊你的文件、笔记甚至网页内容。它基于RAG技术,结合大语言模型(LLM)和向量数据库,让你能轻松上传各种文件,然后通过自然语言跟它们“对话”,提取信息、生成答案。
功能亮点
Quivr 的核心功能可以总结为以下几点:
- 文件对话:上传PDF、TXT、Markdown、Docx、PPTx等几乎任何格式的文件,Quivr 能解析并让你像跟ChatGPT一样“问答”文件内容。比如,扔进去一本教材,马上就能问:“第三章讲了啥?”
- 灵活的模型支持:支持多种LLM,包括OpenAI的GPT-4、Anthropic的Claude、Mistral、Llama,甚至本地模型(通过Ollama)。想用哪个模型,随你挑!
- 向量存储多样性:支持PGVector、Faiss、Weaviate等向量数据库,方便把文件转成向量,加速检索。
- 高度可定制:你可以加互联网搜索、自定义解析器、甚至集成外部工具,打造专属的RAG流程。
- 开源与隐私:完全开源,支持本地部署,数据全在你掌控,适合注重隐私的开发者。
应用场景
Quivr 的用途非常广,比如:
- 个人知识管理:把论文、笔记、会议记录丢进去,随时问问题,整理思路。
- 企业效率工具:团队可以用它构建内部知识库,快速查询文档或生成报告。
- 开发者原型:想快速搞个AI聊天机器人?Quivr 提供现成的RAG框架,省去从零搭建的麻烦。
- 教育与研究:学生可以用它总结文献,研究人员可以用它管理实验数据。
具体例子?想象一下,你上传了一堆PDF合同,Quivr 能帮你秒答:“哪份合同提到‘2025年到期’?”或者扔进去一堆代码注释,它能帮你整理出关键逻辑。够酷吧?
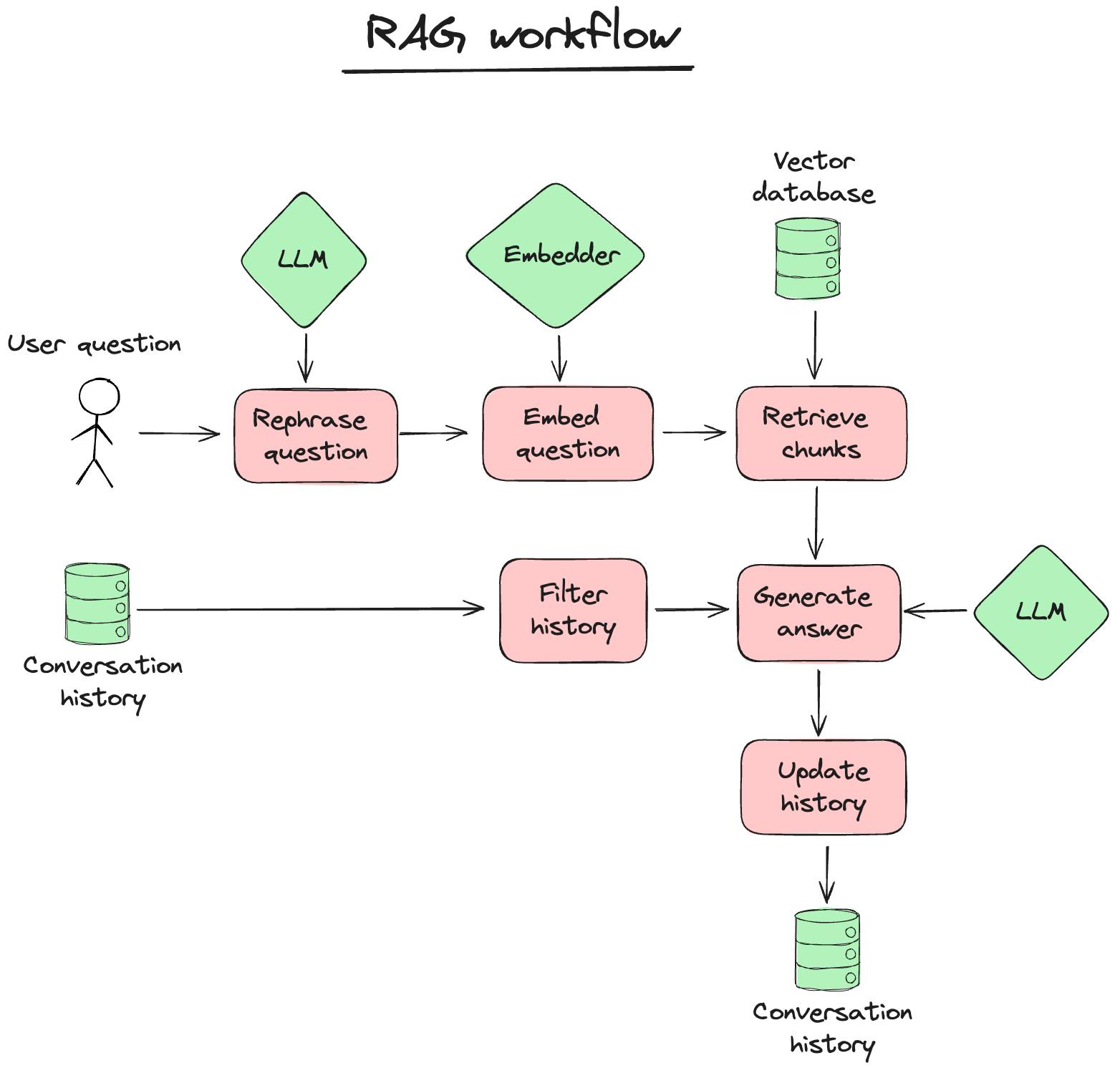
二、技术架构:Quivr 的“神经网络”
Quivr 的架构就像一个精巧的AI大脑,核心是RAG流程:先检索(Retrieval),再生成(Generation)。它把文件解析、向量化和LLM推理整合得无缝衔接。以下是它的架构拆解:
1. 数据摄入与解析
- 文件解析:通过自家的 MegaParse 工具,Quivr 把PDF、Docx、PPTx等文件转成适合LLM的结构化数据,保证信息不丢失。
- 网页爬取:支持从URL提取内容,自动解析网页文本,存进知识库。
- 多模态支持:除了文本,还能处理Markdown、CSV,甚至计划支持音频和视频(还在开发中)。
2. 向量存储与检索
- Quivr 用向量数据库(比如PGVector或Faiss)把解析后的文本转成向量,方便快速检索。
- 检索时,用户的查询会被编码成向量,在数据库中找到最相关的文档片段,精准又高效。
3. 生成与推理
- 检索到的内容会跟用户的问题一起喂给LLM,生成自然语言答案。
- 支持多种模型接口(OpenAI、Anthropic、Ollama等),开发者可以根据预算和需求切换模型。
4. 可扩展接口
- 提供API和SDK,方便集成到现有项目。
- 支持自定义工作流,比如加个互联网搜索模块,或者用工具增强LLM的推理能力。
整个架构就像一个“文件→向量→答案”的流水线,既高效又灵活。
三、核心模块实现逻辑:打开Quivr的“黑盒”
Quivr 的核心模块可以分为三部分:解析、检索和生成。我们用通俗的语言讲讲它们的逻辑:
1. MegaParse(文件解析)
- 逻辑:MegaParse 像个“文件拆解大师”,把PDF、Docx等复杂格式转成纯文本或JSON,保留结构(比如标题、段落)。它会把文本切成小块(chunking),方便后续向量化。
- 代码示例:Quivr 提供简单的Python接口,比如:
解析后的数据直接喂给向量数据库。python
from megaparse import MegaParse parser = MegaParse() parsed_data = parser.parse("contract.pdf")
2. Brain(RAG核心)
- 逻辑:Brain 是 Quivr 的核心类,负责把文件转成向量、存进数据库,然后根据用户查询检索相关内容,最后调用LLM生成答案。它就像一个“知识管理员”,把检索和生成串联起来。
- 代码示例:一个简单的RAG流程长这样:
背后,Brain 会把文件向量化、存进Faiss或PGVector,然后用LLM推理。python
from quivr_core import Brain brain = Brain.from_files(name="my_knowledge", file_paths=["doc.pdf"]) answer = brain.ask("总结这份文档") print(answer)
3. LLM 集成
- 逻辑:Quivr 通过统一的API调用不同LLM(比如OpenAI、Mistral)。开发者可以指定模型和参数,比如最大token数或温度。
- 实现:用类似
litellm的库屏蔽不同模型的接口差异,代码里只需一行切换模型:pythonbrain.set_llm("gpt-4") # 或者 "mistral" 或 "ollama/llama3"
4. 扩展模块
- 支持互联网搜索(通过插件)、自定义解析器和工具调用,开发者可以扩展Brain的功能,比如让它调用外部API或执行代码。
这些模块让 Quivr 既简单又强大,核心逻辑就是“解析→存储→检索→生成”,但封装得非常友好。
四、技术栈:熟悉的Python生态
Quivr 的技术栈对Python开发者来说简直是“老朋友”,几乎没有额外学习成本:
- 编程语言:Python(3.8+)。
- 核心框架:LangChain(RAG流程)、FastAPI(后端API)、Pydantic(数据验证)。
- LLM支持:OpenAI、Anthropic、Mistral、Ollama(本地模型)。
- 向量数据库:PGVector、Faiss、Weaviate(可选)。
- 文件解析:MegaParse(自研),支持PDF、Docx、PPTx、TXT、Markdown等。
- 部署方式:Docker(一键部署)、Supabase(数据库托管)、Vercel/AWS(云部署)。
- 其他依赖:psycopg2(PostgreSQL驱动)、numpy、tqdm等。
如果你会用Python和FastAPI,Quivr 的技术栈上手基本无压力。唯一可能需要适应的是向量数据库的配置,但官方文档和示例很详细。
五、上手难度:小白也能玩吗?
1. 适合人群
Quivr 的目标用户是有一定编程基础的开发者,尤其是:
- 熟悉Python,了解过LangChain或FastAPI。
- 对RAG或向量数据库有基本概念(比如知道啥是embedding)。
- 想快速搭建一个AI知识库或聊天机器人。
如果你完全没接触过AI框架,可能需要先补点RAG和LLM的基础知识,但Quivr 的设计非常注重“开箱即用”,降低了不少门槛。
2. 安装与配置
Quivr 提供了多种部署方式,最简单的是Docker:
bash
git clone https://github.com/QuivrHQ/quivr.git
cd quivr
docker-compose up想本地开发?用pip装依赖:
bash
pip install quivr-core需要Supabase(托管数据库)或Ollama(本地模型)?官方有详细教程,比如配置Supabase的API密钥:
bash
cp .backend_env.example backend/.env
# 编辑 backend/.env,填入 Supabase URL 和密钥3. 学习曲线
- 简单任务:跑官方示例(比如上传PDF问问题)只需要几小时,跟着文档走就行。
- 进阶任务:自定义RAG流程(比如加搜索或新模型)需要理解向量数据库和LLM,可能要几天。
- 硬件要求:本地跑小模型(Ollama)需要8GB内存,GPU可选;云部署几乎无硬件限制。
总体来说,Quivr 的上手难度偏低,官方文档清晰(quivr.app/docs),社区活跃(Discord、GitHub Issues),还有37k+的Star背书,遇到问题不怕没人答。
六、与其他项目的对比:Quivr 有啥特别?
RAG框架市场竞争激烈,比如LangChain、LlamaIndex、Haystack,那 Quivr 为啥能脱颖而出?我们来对比一下:
| 框架 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|
| Quivr | 开箱即用,文件支持广,模型和向量库灵活,社区活跃,注重隐私 | 功能深度不如LangChain,部分多模态支持还在开发 | 个人知识库、快速原型、企业小团队 |
| LangChain | 生态最全,工具丰富,适合复杂Agent开发 | 学习曲线陡,配置复杂,初学者易迷路 | 复杂AI应用、大型企业项目 |
| LlamaIndex | 专注于RAG,索引优化强,文档管理高效 | 偏学术化,模型支持稍弱,社区不如Quivr活跃 | 研究、文档密集型应用 |
| Haystack | 搜索驱动,NLP任务优化好,模块化设计 | 对非搜索任务支持有限,Python生态不如Quivr | 搜索类应用、问答系统 |
Quivr 的优势:
- 简单上手:相比LangChain的“万能工具箱”,Quivr 更专注RAG,配置少,效果快。
- 文件多样性:MegaParse 让它能轻松处理PDF、PPTx等复杂格式,比LlamaIndex更“接地气”。
- 开源生态:37k+ Star,活跃社区,文档和示例多,适合个人和初创团队。
- 隐私友好:支持本地部署,数据不离本地,适合对安全敏感的用户。
不足:相比LangChain,Quivr 的Agent功能和工具集成稍弱,超复杂场景可能需要额外定制。
七、总结:为啥要试试 Quivr?
Quivr 就像一个“AI知识管家”,用RAG技术帮你把零散的文件、笔记变成可对话的“第二大脑”。它的架构清晰,模块化设计让开发者能快速上手;技术栈贴近Python生态,几乎零学习成本;上手难度低,文档和社区支持给力。无论你是想整理个人知识库,还是快速搭个企业级AI助手,Quivr 都能省下不少时间和精力。
更棒的是,Quivr 完全开源,部署灵活,数据隐私有保障。如果你对AI知识管理感兴趣,或者想体验一把“跟文件聊天”的快感,不妨去GitHub点个Star,跑跑示例代码,说不定它会成为你2025年的效率神器!
最后小彩蛋:Quivr 的名字灵感来自“quiver”(箭袋),寓意“装满知识的箭,随时射出答案”。试试看,也许它会成为你AI开发路上的“神射手”!
参考资料:
- Quivr 官方 GitHub 仓库:https://github.com/QuivrHQ/quivr
- Quivr 文档:https://quivr.app/docs
- 社区讨论:GitHub Issues、Discord