探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器

在 AI 技术席卷全球的今天,语音合成和变声技术早已不是科幻电影的专属。想让你的二次元老婆开口唱歌?或者让自己的声音变成动漫角色的腔调?今天,我们来聊聊一个超酷的开源项目——so-vits-svc(SoftVC VITS Singing Voice Conversion),一个专注于歌声转换的 AI 工具。这个项目不仅功能强大,还完全开源,适合对 AI 和音乐感兴趣的小伙伴一探究竟!
1. so-vits-svc 是什么?
so-vits-svc 是一个基于 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)的歌声转换(Singing Voice Conversion, SVC)项目,专注于将一段歌声的音色转换为另一个音色,同时保留原始的音调和情感。简单来说,你可以用它把自己的歌声变成动漫角色的声音,或者让一个角色的声音“翻唱”另一首歌!
这个项目由 svc-develop-team 开发,最初的目的是让开发者心爱的动漫角色“开口唱歌”。它与传统的文本到语音(TTS)技术不同,专注于歌声转换,因此更适合音乐创作、二次元文化和 AI 实验场景。项目完全开源,托管在 GitHub 上(地址:https://github.com/svc-develop-team/so-vits-svc),拥有超过 26.4k 的 Star 和 4.9k 的 Fork,社区活跃度非常高!
2. Ak功能一览
so-vits-svc 的核心功能可以用“强大”两个字来形容,以下是它的几个亮点:
-
歌声音色转换
-
高质量输出
-
自动音高预测
-
实时转换支持
-
声线融合与编辑
-
模型压缩
3. 技术栈揭秘
so-vits-svc 的技术栈可以说是 AI 领域的“硬核”集合,适合对深度学习和语音处理有一定了解的开发者。以下是主要技术点:
项目还支持 K-Means 聚类 减少音色泄漏,新增 FCPE(Fast Context-based Pitch Estimator) 作为实时音高预测器,技术前沿感十足!
4. 搭建难度:新手友好吗?
so-vits-svc 的搭建难度属于 中等偏高,需要一定的 Python 和深度学习基础,但官方文档和社区支持让新手也能上手。以下是搭建的步骤和难度分析:
搭建步骤
- 环境准备:
- 下载预训练模型:
- 数据集准备:
- 训练与推理:
- 进阶功能:
- 使用 MoeVoiceStudio 编辑 f0 曲线或混合声线。
- 尝试实时转换或模型压缩。
注意事项
- 版权问题:数据集需自行解决授权问题,避免使用未授权音频。发布转换结果时,需明确标注输入源(如原视频/音乐链接)。
- 硬件需求:无 GPU 的用户可尝试 CPU 推理,但速度较慢。WSL 用户需额外配置音频设备。
- 社区支持:项目已归档(2023 年 11 月停止更新),但 fork 项目(如 voicepaw/so-vits-svc-fork)仍在维护,社区活跃。
5. 应用场景:你的创意舞台
so-vits-svc 的应用场景非常广泛,尤其适合以下人群:
- 二次元爱好者:让动漫角色翻唱经典歌曲,制作同人作品。
- 音乐创作者:生成独特的虚拟歌手声线,创作原创音乐。
- AI 研究者:探索歌声转换的前沿技术,尝试模型优化。
- 直播/娱乐:通过实时转换打造趣味直播内容(如虚拟主播)。
- 教育/实验:用于语音合成教学或 AI 技术展示。
例如,你可以用 so-vits-svc 让初音未来“唱”一首周杰伦的歌,或者把自己的声音变成《鬼灭之刃》炭治郎的音色,创意无限!

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日

轻松玩转 AI 克隆声音:探秘 GitHub 开源项目 MockingBird
2025年04月14日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
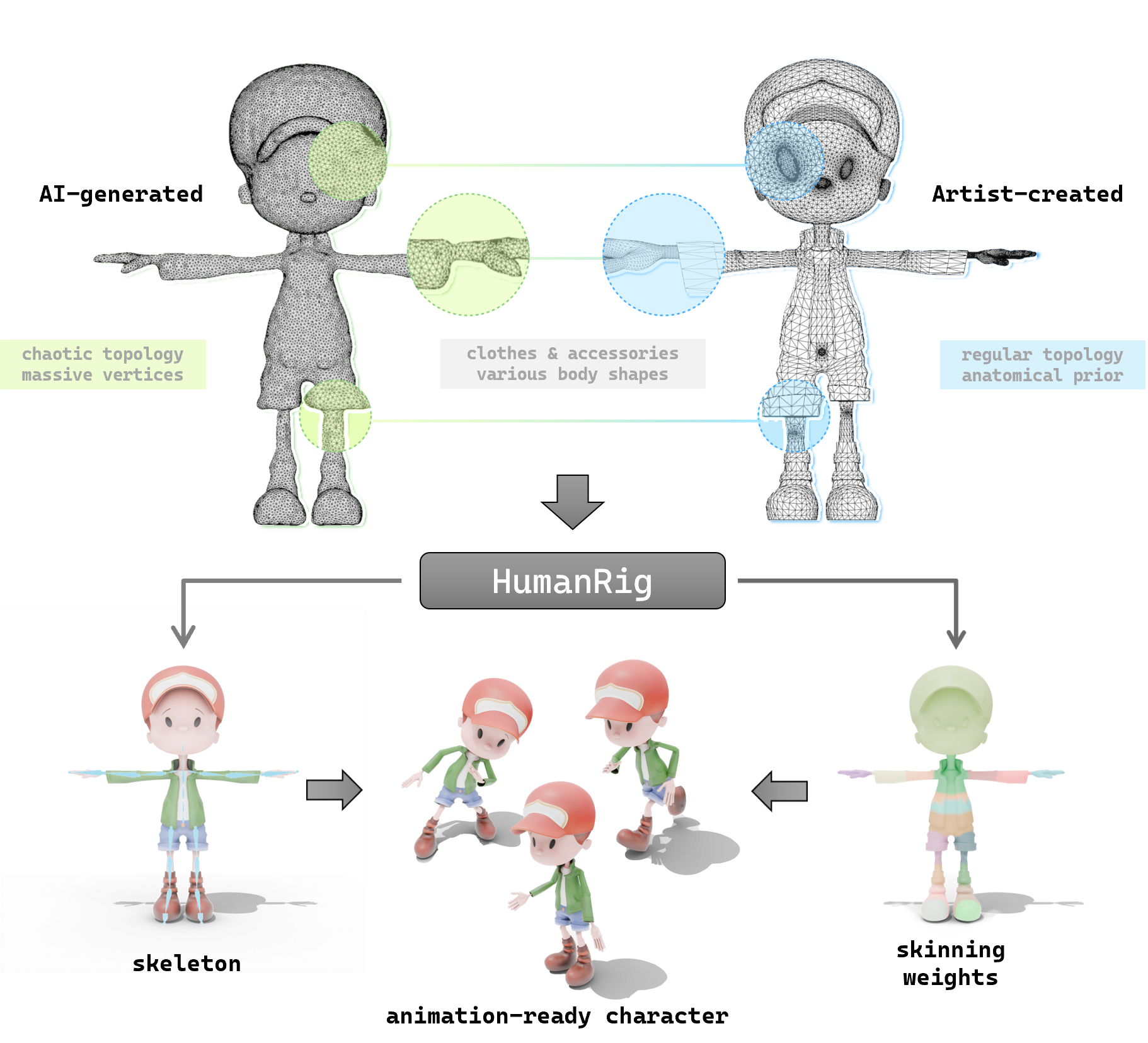
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日