FramePack:让视频生成像玩游戏一样简单!
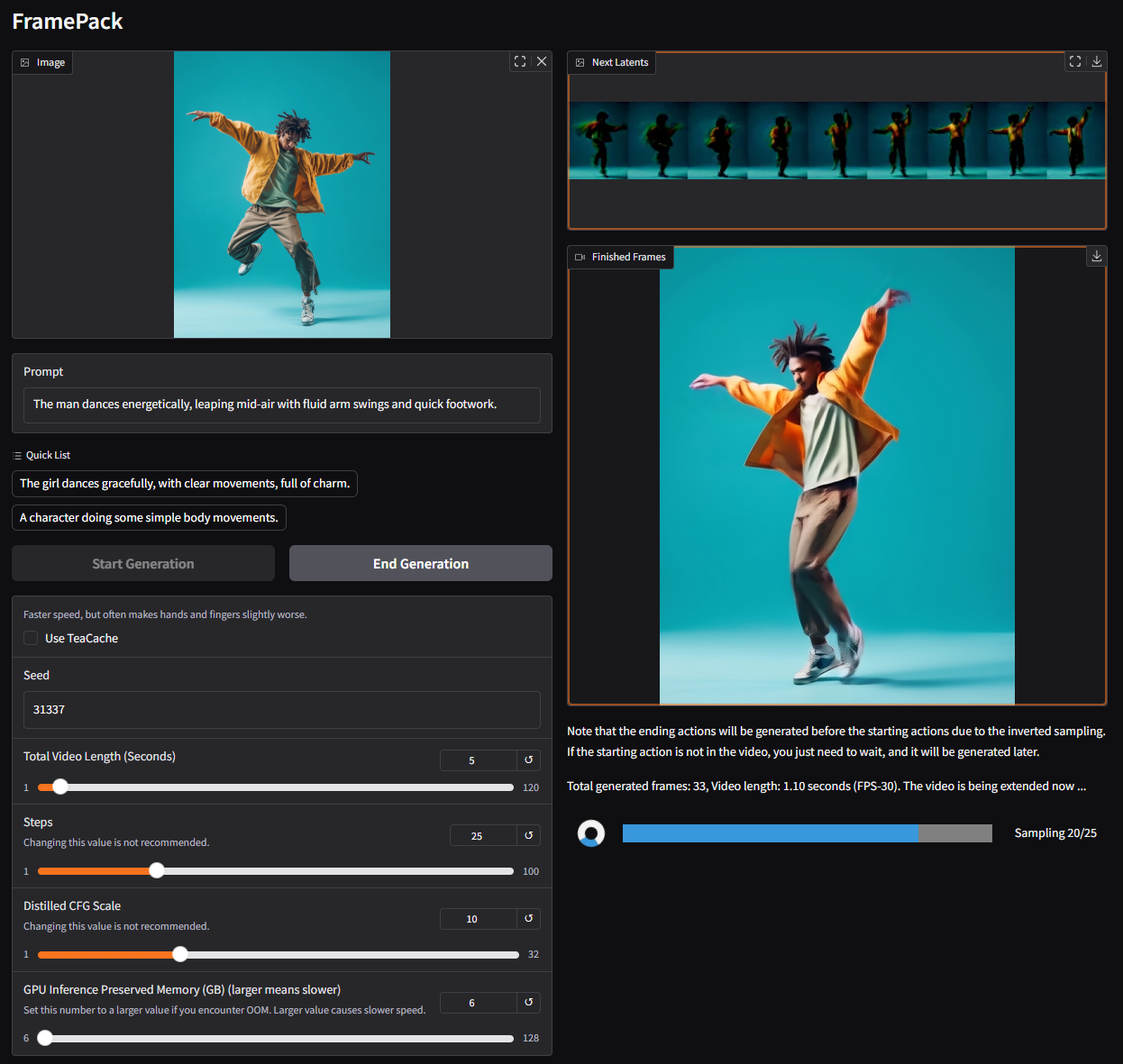
如果你对 AI 视频生成感兴趣,想在自己的电脑上搞点炫酷的视频创作,那今天要介绍的这个开源项目——FramePack,绝对值得你关注!FramePack 是一个由大佬 lllyasviel 开发的项目,目标是让视频扩散模型(Video Diffusion)变得更“接地气”,能在消费级 GPU 上跑得飞起。接下来,我们就来聊聊这个项目的功能、技术栈、实现逻辑,以及上手难度,带你快速了解 FramePack 的魅力!
1. FramePack 能干啥?功能与应用场景
FramePack 的核心功能是从图像生成视频(Image-to-Video, I2V),通过下一帧预测(Next-Frame Prediction)技术,逐步生成连贯的视频内容。简单来说,你给它一张图片,写个提示词(比如“女孩优雅地跳舞”),它就能生成一段动态视频,画面流畅,动作自然。
主要功能:
- 超高效视频生成:FramePack 通过压缩输入上下文,生成任意长度的视频,内存占用几乎不随视频长度增加。1 分钟 30fps 的视频(1800 帧),只需 6GB 显存!
- 支持消费级硬件:专为 NVIDIA RTX 30XX/40XX/50XX 系列 GPU 优化,最低 6GB 显存就能跑,笔记本也能玩。
- 渐进式生成:视频是一秒一秒生成的,生成过程可见,随时调整参数。
- 用户友好界面:基于 Gradio 的 UI,上传图片、输入提示词,点击生成,傻瓜式操作。
应用场景:
- 创意内容创作:生成短视频、动画片段,适合自媒体、Vlog 创作者。
- 游戏与影视预览:快速生成角色动作或场景动画,验证创意。
- AI 艺术实验:艺术家可以用它探索图像到视频的动态效果。
- 教育与研究:研究视频扩散模型的实现,学习 AI 模型优化技巧。
举个例子:你有一张“武士挥剑”的图片,想让它动起来,变成一段“武士挥舞发光宝剑”的视频,FramePack 就能帮你实现,生成的视频还能保持长时间的连贯性!
2. 技术架构:FramePack 的“内功心法”
FramePack 的核心在于下一帧预测模型,通过压缩上下文信息,让视频生成像图像扩散一样高效。它的架构可以简单分为以下几层:
-
输入层:
- 接受一张图像和文本提示词(Prompt)。
- 文本通过 CLIP(或改进版 Siglip-so400m-patch14)编码为语义向量,图像通过预训练视觉模型编码。
-
核心模型:
- 基于 HunyuanVideo 模型改进,融入下一帧预测网络。
- 通过“打包”(Packing)技术,将输入上下文压缩为固定长度,解决长视频生成时的内存瓶颈。
-
生成层:
- 渐进式生成每秒视频片段(1 秒 ≈ 30 帧)。
- 使用扩散模型(Diffusion Model)预测下一帧,保持动作连贯。
-
输出层:
- 生成的视频片段存储在输出文件夹,Gradio UI 提供实时预览。
- 支持调整分辨率、帧率等参数。
整个架构就像一个“视频打印机”,一张图进来,打印出一帧一帧的动态画面,内存占用却始终稳定。
3. 核心模块实现逻辑
FramePack 的核心创新在于上下文打包(Packing Input Frame Context),让我们来拆解一下它的实现逻辑:
-
上下文压缩:
- 传统视频扩散模型需要加载所有帧的上下文,内存占用随视频长度暴增。
- FramePack 用一个固定长度的上下文向量表示历史帧信息,生成新帧时只依赖这个向量,大幅降低内存需求。
-
下一帧预测:
- 模型基于当前帧和上下文向量,预测下一帧的像素分布。
- 使用改进的 Hunyuan 模型(13B 参数),结合 Siglip 视觉编码器,确保生成的帧与提示词高度相关。
-
优化内存管理:
- 支持多种注意力机制(PyTorch Attention、xformers、flash-attn、sage-attention),默认用 PyTorch Attention。
- sage-attention 等优化可加速生成,但可能略影响质量,建议先用默认设置。
-
渐进式生成:
- 每次生成 1 秒视频,完成后自动扩展到下一秒。
- 用户可在 UI 中看到每段的生成进度和潜在预览(Latent Preview)。
这种设计让 FramePack 像搭积木一样,一块一块拼出长视频,既高效又稳定。
4. 技术栈:FramePack 的“工具箱”
FramePack 的技术栈以 Python 和 PyTorch 为主,依赖一些主流 AI 库和工具:
- 编程语言:Python(推荐 3.12,但需注意库版本兼容性)。
- 核心框架:
- PyTorch:用于模型构建和推理,支持 CUDA 加速。
- torchvision/torchaudio:处理图像和潜在音频输入。
- 模型相关:
- HunyuanVideo:基础视频扩散模型。
- CLIP/Siglip:文本和图像编码。
- Diffusers:Hugging Face 的扩散模型库,简化模型加载。
- 前端界面:
- Gradio:提供交互式 Web UI,方便用户操作。
- 优化工具:
- xformers/flash-attn/sage-attention:加速注意力机制。
- Triton:优化 GPU 计算(20 系 GPU 可能有兼容问题)。
- 其他依赖:numpy、scipy、av(音视频处理),requirements.txt 中列出完整列表。
硬件要求:
- GPU:NVIDIA RTX 30XX/40XX/50XX,6GB 显存起步。
- OS:Linux 或 Windows(Windows 版已于 2025 年 4 月 18 日发布)。
5. 上手难度:新手友好吗?
FramePack 的上手难度属于中等偏高,适合有一定 Python 和 AI 基础的人。以下是详细分析:
安装过程:
- 步骤:
- 克隆仓库:
git clone https://github.com/lllyasviel/FramePack.git - 创建虚拟环境并激活:
python -m venv venv && venv\Scripts\activate - 安装依赖:
pip install -r requirements.txt - 安装 PyTorch(需匹配 CUDA 版本):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 - 运行 Gradio UI:
python demo_gradio.py
- 克隆仓库:
- 常见坑:
- Python 版本兼容性(3.12 可能需调整 requirements.txt)。
- CUDA 版本需与 GPU 匹配,RTX 5090 用户可能遇到报错。
- 20 系 GPU 对 Triton 支持不佳,可能需禁用 flash-attn。
- 耗时:首次安装(含下载模型)约 30 分钟,后续运行很快。
使用难度:
- UI 操作简单,上传图片、输入提示词即可生成。
- 提示词需参考官方示例(如“女孩优雅地跳舞,动作清晰,充满魅力”),新手可能需多试几次。
- 生成 3 秒视频(320x320)约 20 分钟,高分辨率需调整内存参数。
建议:
- 熟悉 Python 和 PyTorch 的开发者,1 小时内可跑通。
- 新手建议先看 Reddit 上的安装教程(如 u/CeFurkan 的视频)或等一键安装包。
- 遇到 CUDA 错误,可设置
CUDA_LAUNCH_BLOCKING=1调试。
6. 与其他项目的对比
FramePack 并不是唯一的视频生成工具,我们来对比几个热门项目:
| 项目 | FramePack | Stable Video Diffusion (SVD) | Runway Gen-2 |
|---|---|---|---|
| 类型 | 开源,桌面软件 | 开源,研究向 | 商业,Web 服务 |
| 显存需求 | 6GB(1 分钟视频) | 12GB+(短视频) | 无需本地 GPU |
| 生成方式 | 下一帧预测,渐进式 | 全视频生成 | 云端生成 |
| 硬件支持 | RTX 30XX+ | 高端 GPU | 无硬件要求 |
| 上手难度 | 中等 | 高 | 低 |
| 定制性 | 高(可改代码) | 中 | 低 |
| 社区活跃度 | 高(4.9k Star,223 Fork) | 中 | 无开源社区 |
优势:
- FramePack 的显存需求极低,消费级硬件友好。
- 开源程度高,适合二次开发和研究。
- 渐进式生成便于调试和调整。
劣势:
- 生成速度较慢(3 秒视频约 20 分钟)。
- 安装和调试对新手有一定门槛。
- 20 系 GPU 兼容性问题待解决。
相比 SVD,FramePack 更适合个人电脑;相比 Runway,FramePack 免费且可定制,但生成速度和易用性稍逊。
7. 总结:FramePack 值得一试吗?
FramePack 是一个让人眼前一亮的开源项目,它把视频扩散的门槛拉低到消费级硬件,让普通开发者也能在笔记本上生成炫酷的 AI 视频。它的上下文打包技术和渐进式生成设计,既高效又创新,特别适合想探索 AI 视频生成的朋友。
推荐人群:
- 有 Python 和 PyTorch 基础,想玩 AI 视频生成的开发者。
- 内容创作者,想用 AI 快速生成动态素材。
- AI 研究者,想研究视频扩散模型的优化。
上手建议:
- 先看官方 GitHub 和 Reddit 教程,避免踩坑。
- 从低分辨率(320x320)开始,熟悉后再调高参数。
- 加入 GitHub Discussions,与社区交流经验。
总的来说,FramePack 就像一个“AI 视频打印机”,虽然安装有点小麻烦,但一旦跑起来,生成的视频绝对会让你觉得“值了”!快去 GitHub 克隆一份,试试让你的图片“跳舞”吧!
项目地址:https://github.com/lllyasviel/FramePack
项目主页:https://lllyasviel.github.io/frame_pack_gitpage/
参考资料:

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
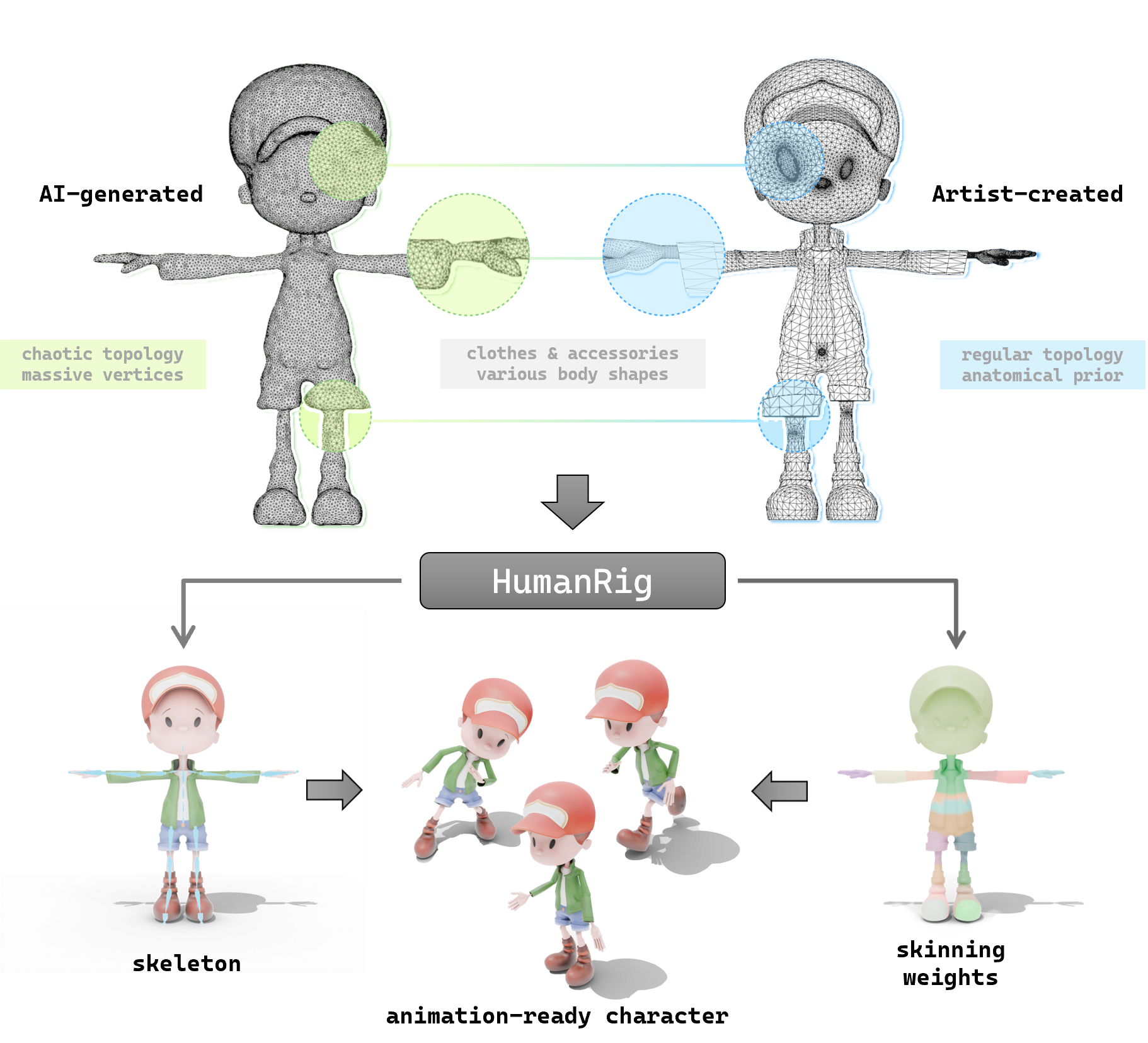
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器
2025年04月22日
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日

让 AI 更懂你的网站:一文读懂 llms-txt 开源项目
2025年04月24日