GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日

什么是GigaTok
GigaTok是一款拥有 30 亿参数的视觉标记器,致力于将视觉分词器扩展至 30 亿参数,用于自回归(AR)图像生成。项目地址为 SilentView/GigaTok,由香港大学和字节跳动 Seed 团队联合开发。
GigaTok 的创新设计理念
GigaTok 的核心在于解决了视觉分词器扩展中的关键难题:随着参数规模增加,潜在空间复杂度上升,导致重建质量提升但生成质量下降。项目通过以下创新点突破这一瓶颈:
- 参数规模的飞跃:GigaTok 拥有高达 30 亿的参数,使其能够精细捕捉图像中的每一个细节,从容应对复杂场景。
- 一维分词器:相较于二维分词器,一维分词器在扩展性上更具优势。
- 优先扩展解码器:在扩展编码器和解码器时,优先扩展解码器能显著提升性能。
- 熵损失:引入熵损失以稳定亿级分词器的训练过程。
- 混合架构:采用基于 CNN-Transformer 主干的向量量化(VQ)分词器,兼顾效率与性能。
GigaTok 提供了从 1.36 亿到 29 亿参数的系列分词器,搭配 AR 模型(参数从 1.11 亿到 14 亿),在 256x256 图像上表现出色。例如,29 亿参数的 XL-XXL 分词器搭配 14 亿参数的 GPT-XXL 模型,在 ImageNet 上实现了 gFID 1.98 和 74.0% 的分类准确率。
项目功能
- 分词器系列:提供从 S-S(1.36 亿参数)到 XL-XXL(29 亿参数)的多种分词器,适用于不同规模需求。
- AR 模型支持:包括 GPT-B(1.11 亿参数)、GPT-XL(7.75 亿参数)和 GPT-XXL(14 亿参数)等多种 AR 模型。
- 全面评估框架:支持重建(rFID)、生成(gFID)和线性探查评估,超越传统重建目标。
- 实验性实现:集成旋转技巧等实验性功能,增强训练灵活性。
- 开源资源:提供预训练检查点、配置文件和详细文档,方便用户快速上手。
环境配置
搭建 GigaTok 环境需以下步骤:
- 确保 CUDA 12.1 已安装。
- 创建 Conda 环境:
bash
conda create -n gigatok python=3.9 conda activate gigatok - 安装依赖:
bash
bash env_install.sh - 配置环境变量:编辑
set_env_vars.sh,设置PROJECT_ROOT和TORCH_RUN_PATH。 - 评估环境:为评估任务创建单独环境(
tok_eval)并安装 TensorFlow、NumPy 和 SciPy。
使用方法
1. 分词器重建
用于评估分词器的图像重建能力:
bash
# 设置环境变量
. set_env_vars.sh
export TOK_CONFIG="configs/vq/VQ_XLXXL256.yaml"
export VQ_CKPT=results/ckpts/VQ_XLXXL256_e300.pt
# 运行定性重建
DATA_PATH=${PROJECT_ROOT}/tests/
SAMPLE_DIR=results/reconstructions/
gpus=1 PORT=11086 bash scripts/reconstruction.sh \
--quant-way=vq \
--data-path=${DATA_PATH} \
--image-size=256 \
--sample-dir=$SAMPLE_DIR \
--vq-ckpt=${VQ_CKPT} \
--model-config ${TOK_CONFIG} \
--qualitative \
--lpips \
--clear-cache定量评估见 详细说明。
2. 类条件生成
使用 AR 模型生成特定类别图像,例如大熊猫(388)、白头鹰(22)等:
bash
. set_env_vars.sh
export TOK_CONFIG="configs/vq/VQ_XLXXL256.yaml"
export VQ_CKPT=results/ckpts/VQ_XLXXL256_e300.pt
export LM_CKPT=results/ckpts/GPT_B256_e300_VQ_XLXXL.pt
CFG=4.0 CFG_SCHEDULE="constant" GPT_MODEL="GPT-B"
SAMPLE_DIR=results/gpt_eval/GPT_B256_e300_VQ_XLXXL
bash scripts/sample_c2i_visualization.sh \
--quant-way=vq \
--image-size=256 \
--sample-dir=$SAMPLE_DIR \
--vq-ckpt ${VQ_CKPT} \
--tok-config ${TOK_CONFIG} \
--gpt-model ${GPT_MODEL} \
--cfg-schedule ${CFG_SCHEDULE} \
--cfg-scale ${CFG} \
--gpt-ckpt ${LM_CKPT} \
--precision fp16 \
--class-idx "22,388,90,978" \
--per-proc-batch-size 8 \
--qual-num 403. 模型下载
项目提供多个预训练检查点,涵盖不同规模的分词器和 AR 模型。例如:
完整列表见项目文档。
项目结构与依赖
- 代码库:基于 LlamaGen,参考 REPA、DETR 等。
- 配置文件:分词器和 AR 模型配置位于
configs/vq/,如VQ_XLXXL256.yaml。 - 依赖:Python 3.9、CUDA 12.1、PyTorch、TensorFlow(评估用)、NumPy、SciPy 等。
总结
GigaTok 是视觉分词器领域的里程碑项目,通过语义正则化、一维分词器等创新,成功将分词器扩展至 30 亿参数,并在图像生成任务中实现突破。其开源代码、预训练模型和详细文档为研究者和开发者提供了宝贵资源。立即访问 GitHub 仓库 或 项目页面,探索 GigaTok 的强大功能!
©版权声明: 本网站(猫目,网址:https://maomu.com/ )所有内容,包括但不限于文字、图片、图标、数据、产品描述、页面设计及代码,均受中华人民共和国著作权法及国际版权法律保护,归本站所有。未经书面授权,任何个人、组织或机构不得以任何形式复制、转载、修改、传播或用于商业用途。 对于任何侵犯本网站版权的行为,我们保留追究其法律责任的权利,包括但不限于要求停止侵权、赔偿损失及提起诉讼。
热门文章

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日
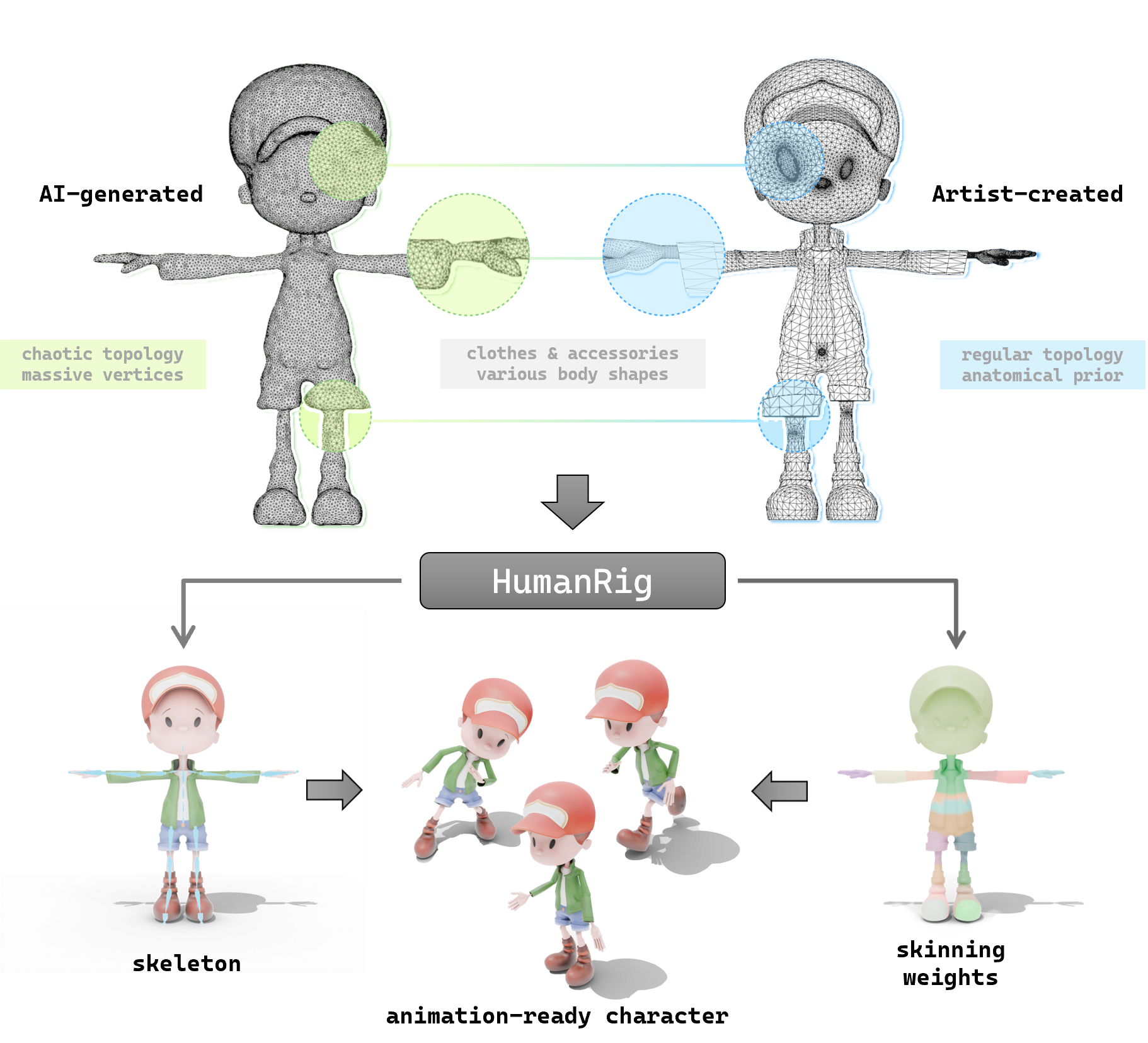
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器
2025年04月22日
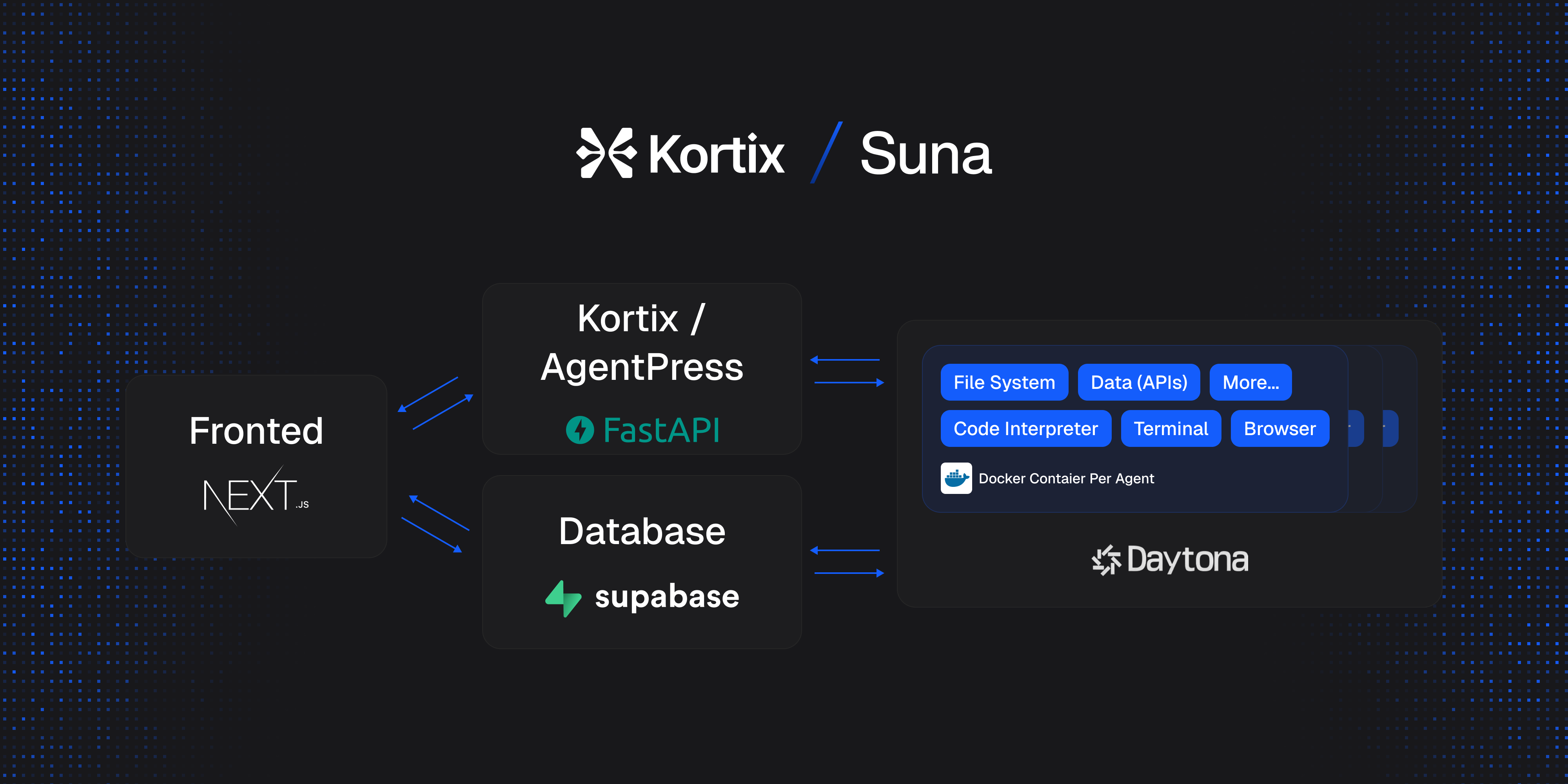
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日

让 AI 更懂你的网站:一文读懂 llms-txt 开源项目
2025年04月24日