技术与旋律融合:腾讯发布AI音乐生成模型LeVo,引发业界关注

LeVo:腾讯AI Lab 开源音乐生成模型的技术突破
引言
LeVo(Learning Voice from Music)是腾讯AI Lab 推出的一款开源音乐生成模型,旨在通过人工智能技术革新音乐创作方式。作为 SongGeneration 仓库(https://github.com/tencent-ailab/SongGeneration)的核心实现,LeVo 结合先进的语言模型(LeLM)与高效音乐编解码器,实现了高质量、高灵活性的音乐生成。本文将重点介绍 LeVo 的技术架构、核心功能、应用场景以及其对 AI 音乐创作领域的深远意义。
LeVo 的技术架构
LeVo 模型通过创新的架构设计,实现了音质、音乐性和生成效率的完美平衡。以下是其核心技术亮点:
1. MuCodec:超低比特率音乐编解码器
LeVo 采用了一种名为 MuCodec 的高效音乐编解码器,能够以 25Hz 和 0.35kbps 的超低比特率实现 48kHz 双通道音频的高保真重建。这种低比特率设计大幅降低了计算复杂度,使得语言模型能够专注于音乐语义的建模,同时保留了音频的细节和质感,为高质量音乐生成奠定了基础。
2. 混合与双轨 token 并行预测
LeVo 创新性地引入了“混合优先,双轨其次”的 token 处理策略:
- 混合 token:将人声与伴奏信息融合,生成和谐统一的音轨,确保整体音乐的连贯性。
- 双轨 token:分别编码人声和伴奏,提升生成音轨的独立性和清晰度。
通过并行预测两种 token 类型,LeVo 有效避免了 token 间的干扰,显著提升了音质和音乐结构的完整性。
3. 多维度偏好对齐
LeVo 通过半自动数据构建方法,生成大规模偏好数据对,优化了以下关键维度:
- 音乐性:确保生成的音乐在旋律、节奏和和声上符合预期风格。
- 歌词对齐:实现歌词与音乐的精准同步,提升歌曲的表达力。
- 提示一致性:根据用户输入的文本提示,生成符合指定情感、风格和主题的音乐。
这种多维度对齐技术使 LeVo 能够生成高度符合用户意图的音乐作品。
4. 三阶段训练范式
LeVo 采用三阶段训练流程,确保模型的鲁棒性和多样性:
- 预训练:在包含百万首歌曲的超大规模数据集(如 Million Song Dataset)上进行预训练,学习多样化的音乐结构和风格。
- 模块化扩展训练:通过模块化方式扩展模型能力,适配不同任务需求。
- 多偏好对齐训练:利用偏好数据对模型进行微调,提升生成结果的针对性和用户满意度。
这一训练范式使 LeVo 能够处理中英文歌曲等多种音乐类型,生成结果兼具多样性和高质量。
5. 紧凑的 3B 参数模型
LeVo 仅拥有约 30 亿个参数,却在音质、音乐性和生成速度上表现出色。其紧凑的模型规模降低了计算资源需求,使其在普通 GPU(如显存 ≥ 16GB)上即可高效运行,极大降低了使用门槛。
LeVo 的核心功能
LeVo 的设计以用户需求为核心,提供了灵活且直观的音乐生成功能,适用于从专业音乐人到普通爱好者的广泛用户群体。以下是其主要功能:
1. 文本引导的音乐生成
用户可以通过简单的文本提示(如“浪漫的钢琴爵士”或“激昂的摇滚乐”)生成完整的音乐作品。LeVo 能够解析提示中的风格、情感和节奏要求,生成符合预期的音乐,极大地降低了创作门槛。
2. 风格跟随与参考音频
LeVo 支持基于参考音频(建议 10 秒以上,优先选择歌曲高潮部分)生成风格一致的音乐。无论是流行、古典还是民族音乐,LeVo 都能快速捕捉参考音频的风格特征,生成与之匹配的新曲。这一功能特别适合需要快速生成配乐的场景,如视频剪辑或游戏开发。
3. 多轨生成与分离
LeVo 支持将人声和伴奏分离为独立音轨,生成结果可直接用于后期混音或编辑。这种多轨生成能力使 LeVo 从单纯的生成工具升级为专业音乐制作工具,满足复杂创作需求。
4. 歌词与音乐精准对齐
LeVo 接受以 JSON Lines 格式输入的歌词(需标注 [Verse]、[Chorus] 等结构),并实现歌词与音乐的精准对齐。若输入歌词较短,模型会自动填充内容以延长歌曲时长,确保结构完整。这一功能特别适合需要快速生成完整歌曲的场景。
5. 多维度音乐属性控制
LeVo 允许用户通过文本描述控制多种音乐属性,包括:
- 性别:如男声、女声。
- 音色:如明亮、温暖、深沉。
- 流派:如流行、爵士、电子。
- 情感:如欢乐、悲伤、浪漫。
- 乐器:如吉他、钢琴、鼓。
- BPM:如 120 或 140。
这种精细化的控制能力让用户能够生成高度个性化的音乐作品。
安装与运行
LeVo 的开源实现通过 SongGeneration 仓库提供,安装和运行流程简单,适合开发者和创作者快速上手:
-
环境要求:
- Python ≥ 3.8.12
- CUDA ≥ 11.8
- GPU 显存 ≥ 16GB(推荐 24GB 以上以获得最佳性能)
-
安装依赖:
bashpip install -r requirements.txt pip install -r requirements_nodeps.txt --no-deps为加速推理,推荐安装 Flash Attention:
bashpip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -
Docker 部署:
bashdocker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash -
低内存优化:
对于显存较低的设备,可运行generate_lowmem.sh脚本以优化内存使用,避免溢出。
用户还可以通过 Hugging Face 在线 Demo(https://huggingface.co/spaces/tencent/SongGeneration)快速体验 LeVo 的生成效果。
应用场景
LeVo 的高灵活性和高质量输出使其在以下场景中展现出巨大潜力:
- 音乐创作:为音乐人提供灵感草稿,快速生成高质量的歌曲或配乐原型。
- 影视与游戏:生成契合主题的背景音乐或音效,提升作品沉浸感。
- 广告营销:为品牌活动快速生成定制化音乐,增强品牌吸引力。
- 音乐教育:作为教学工具,帮助学生理解音乐结构和创作技巧。
- 个人娱乐:普通用户可通过简单输入创作个性化歌曲,分享至社交平台,增加互动乐趣。
性能与评测
LeVo 在主客观评测中表现出色。在与开源模型(如 YuE、DiffRhythm)和商业模型(如 Suno v4.5、Mureka O1)的对比中,LeVo 在内容欣赏度(CE)、内容实用性(CU)和制作质量(PQ)等指标上位居开源模型前列,部分指标甚至接近或超越商业模型。其在歌词对齐和语音-文本一致性上的表现尤为突出,展现了其在细节处理上的技术优势。
社区反响与未来展望
自 2025 年 6 月通过 SongGeneration 仓库开源以来,LeVo 受到社区的广泛关注。X 平台用户反馈显示,LeVo 在中文音乐生成方面表现尤为出色,生成效果接近 Suno 4.5 水平。然而,部分用户指出模型在某些复杂场景下的稳定性有待提升,这可能是由于当前开源版本非完整模型的限制。
未来,LeVo 有望通过以下方向进一步发展:
- 多语言支持扩展:增强对非中英文音乐风格的支持,覆盖更多全球音乐类型。
- 模型优化:提升生成稳定性和一致性,减少多次尝试的需要。
- 社区驱动创新:借助开源社区的力量,开发更多定制化功能和应用场景。
结论
LeVo 作为腾讯AI Lab 的开源力作,以其高效的 MuCodec 编解码器、并行 token 预测和多维度偏好对齐技术,重新定义了 AI 音乐生成的标准。其紧凑的模型规模、强大的功能和用户友好的设计,使其成为音乐创作领域的强大工具。无论是专业音乐人还是普通用户,LeVo 都提供了从灵感激发到完整创作的全面支持。未来,随着社区的持续贡献和技术的迭代,LeVo 有望进一步推动 AI 音乐创作的普及化与多样化,成为全球音乐生态的重要一环。
参考资料:
- SongGeneration 官方代码仓库:https://github.com/tencent-ailab/SongGeneration
- Hugging Face 模型库:https://huggingface.co/tencent/SongGeneration
- 技术论文:https://arxiv.org/pdf/2506.07520
- 在线体验 Demo:https://levo-demo.github.io/#demo

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
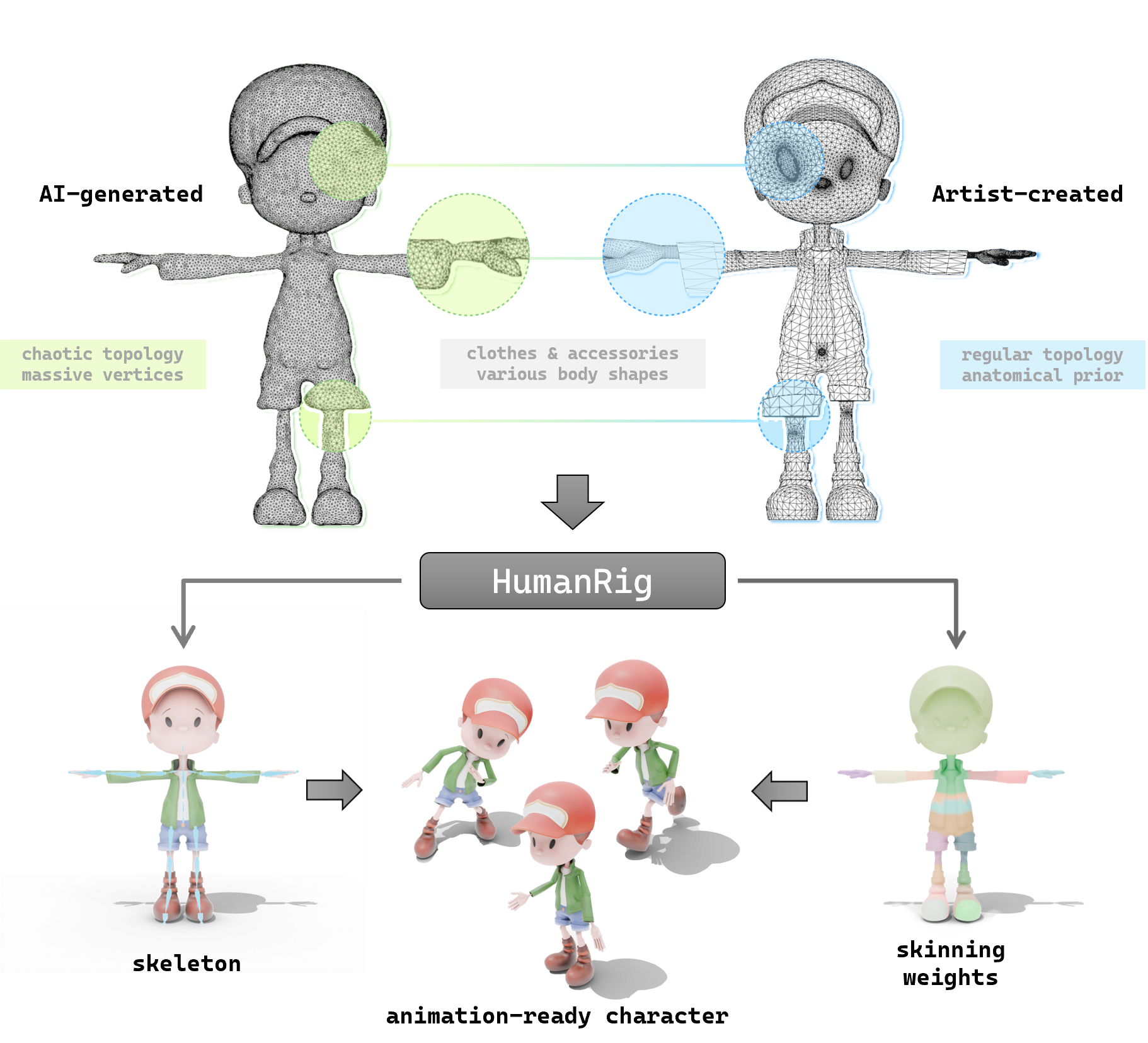
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

Qwen3发布:思深,行速
2025年04月29日

国产 AI 王炸!智谱 GLM-4.5 开源:参数砍半性能反超,API 价格仅 Claude 1/10
2025年07月29日