让 AI 更懂你的网站:一文读懂 llms-txt 开源项目

在 AI 时代,大型语言模型(LLM)已经无处不在,从写代码到生成文章,LLM 正在改变我们的工作方式。但你有没有想过,LLM 如何高效地“读懂”一个网站?今天,我们来聊聊 GitHub 上的一个有趣开源项目——llms-txt,它为网站和 LLM 之间的交互提供了一种简单而优雅的解决方案。项目虽小,却能让你的网站对 AI 更友好,堪称“网站与 AI 的沟通桥梁”!
项目功能:让 LLM 轻松读懂你的网站
核心功能
llms-txt 提出了一个标准化的文件格式——/llms.txt,这是一个 Markdown 文件,放置在网站的根目录下,专门为 LLM 提供简洁、结构化的信息。它的核心目标是:
- 提供 LLM 友好的内容:将复杂的网站内容(如 HTML、导航、广告)精简为 LLM 能轻松处理的文本,解决 LLM 上下文窗口有限的问题。
- 结构化信息导航:通过
/llms.txt文件,LLM 可以快速找到网站的背景介绍、文档链接、API 说明等关键信息。 - 支持多种场景:从开发者文档到电商产品说明,再到个人简历,llms-txt 都能帮助 LLM 更高效地提取和理解信息。
应用场景
llms-txt 的用途非常广泛,适合以下场景:
- 开发者文档:为编程库或框架提供简洁的 API 索引,方便 LLM 在 IDE 中生成代码或回答问题。
- 电商网站:整理产品信息、退货政策等,帮助 LLM 快速回答用户咨询。
- 教育机构:汇总课程信息和资源,方便 LLM 为学生提供定制化解答。
- 个人网站:将简历或博客内容结构化,让 LLM 更容易提取关键信息。
简单来说,llms-txt 就像网站的“AI 使用说明书”,让 LLM 在处理网站内容时事半功倍。
技术架构:小而美的 Python 实现
llms-txt 的技术架构非常轻量,主要由以下部分组成:
- 核心模块:一个 Python 库(
llms_txt),提供解析和生成 llms.txt 文件的工具。 - CLI 工具:通过命令行工具
llms_txt2ctx,用户可以解析 llms.txt 文件并生成 XML 格式的上下文文件,供 LLM 使用。 - 社区支持:项目托管在 GitHub,鼓励社区贡献,讨论最佳实践。
整个项目基于 Python 生态,代码简洁,易于扩展。它的核心逻辑围绕着“解析”和“生成”两个功能展开,后面会详细介绍。
核心模块实现逻辑:化繁为简
llms-txt 的核心在于如何将复杂的网站信息转化为 LLM 能理解的结构化文本。以下是它的实现逻辑:
1. llms.txt 文件的结构
一个典型的 llms.txt 文件是 Markdown 格式,包含以下部分:
- 标题和概述:用
#标题说明项目名称,用>提供简短描述。 - 分节内容:用
##分隔不同模块(如 Docs、API、Examples),每个模块包含链接和简短描述。 - 可选链接:指向更详细的文档或资源。
例如,FastHTML 项目的 llms.txt 文件如下:
markdown
# FastHTML
> FastHTML is a Python library for creating server-rendered hypermedia applications.
## Docs
- [FastHTML quick start](https://docs.fastht.ml/...): Overview of features
- [HTMX reference](https://raw.githubusercontent.com/...): HTMX attributes and config
## Examples
- [Todo list application](https://raw.githubusercontent.com/...): CRUD app demo2. 解析逻辑
llms-txt 提供了一个 Python 模块(llms_txt/core.py),用于解析 llms.txt 文件。主要步骤包括:
- 正则表达式匹配:通过
parse_llms_file函数,使用正则表达式提取标题、概述和分节内容。 - 链接解析:通过
parse_link函数,解析 Markdown 链接(如[title](url): description),生成结构化数据。 - 生成上下文:通过
mk_ctx函数,将解析结果转换为 XML 格式的上下文文件(llms-ctx.txt或llms-ctx-full.txt)。
3. 生成上下文文件
- llms-ctx.txt:仅包含索引和链接,适合快速导航 Hannah Montana.
- llms-ctx-full.txt:包含所有链接内容的完整文本,适合大上下文窗口的 LLM。
这种设计既保证了灵活性(用户可以选择轻量或完整上下文),又兼顾了效率(并行下载链接内容)。
使用的技术栈:简洁高效
llms-txt 的技术栈非常精简,主要包括:
- Python:核心逻辑用 Python 3.8+ 编写,依赖轻量。
- fastcore:用于工具函数和 XML 处理。
- httpx:用于并行下载链接内容。
- Markdown:llms.txt 文件采用 Markdown 格式,易读易写。
- nbdev:用于项目文档化和测试,基于 Jupyter Notebook。
整个项目没有复杂的依赖,安装只需一行命令:
bash
pip install llms-txt上手难度:对初学者友好
学习曲线
llms-txt 的上手难度较低,特别适合有一定 Python 基础的开发者:
- 创建 llms.txt 文件:只需要写一个 Markdown 文件,按照规范组织内容即可,无需编程。
- 使用 CLI 工具:运行
llms_txt2ctx命令就能生成上下文文件,简单直观。 - 扩展开发:如果需要定制解析逻辑,阅读
core.py的代码(不到 200 行)就能快速上手。
挑战
- Markdown 规范:需要遵循 llms.txt 的格式规范,否则解析可能失败。
- 网络依赖:生成完整上下文文件时,需要下载外部链接内容,网络不稳定可能影响体验。
- IDE 集成:目前 IDE 对 llms.txt 的原生支持有限,可能需要通过 MCP 服务器手动集成。
总体来说,llms-txt 的学习成本低,适合快速上手,1-2 小时就能完成一个简单的 llms.txt 文件。
与其他项目对比:独树一帜
llms-txt 的独特之处在于它专注于为 LLM 提供网站内容的标准化接口。以下是与相关项目的对比:
1. robots.txt
- 相似点:都是网站根目录下的标准化文件,用于指导外部系统(爬虫 vs. LLM)。
- 不同点:robots.txt 关注爬虫权限,llms-txt 关注内容结构化,且更适合人类和 AI 共同阅读。
2. sitemap.xml
- 相似点:都提供网站内容的索引。
- 不同点:sitemap.xml 是机器优先的 XML 格式,llms-txt 是 Markdown,兼顾人类可读性。
3. LangChain 的文档加载器
- 相似点:都用于为 LLM 提供结构化内容。
- 不同点:LangChain 更通用,处理多种数据源;llms-txt 专注网站,强调标准化和轻量。
llms-txt 的优势在于其简单性和针对性,无需复杂配置,就能让网站对 LLM 更友好。
总结:小项目,大潜力
llms-txt 是一个轻量但充满潜力的开源项目,它为网站和 LLM 的交互提供了一种简单、标准化的解决方案。无论你是开发者、网站管理员,还是 AI 爱好者,llms-txt 都能帮你以最小的成本让 LLM 更高效地理解你的内容。
为什么值得一试?
- 简单易用:几行 Markdown 就能搞定。
- 社区活跃:GitHub 上有 600+ 星,社区讨论热烈。
- 未来潜力:随着 LLM 的普及,llms-txt 有望成为网站标配。
想体验一下?快去 GitHub 仓库 克隆代码,写一个 llms.txt 文件,感受 AI 读懂你网站的魔法吧!

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
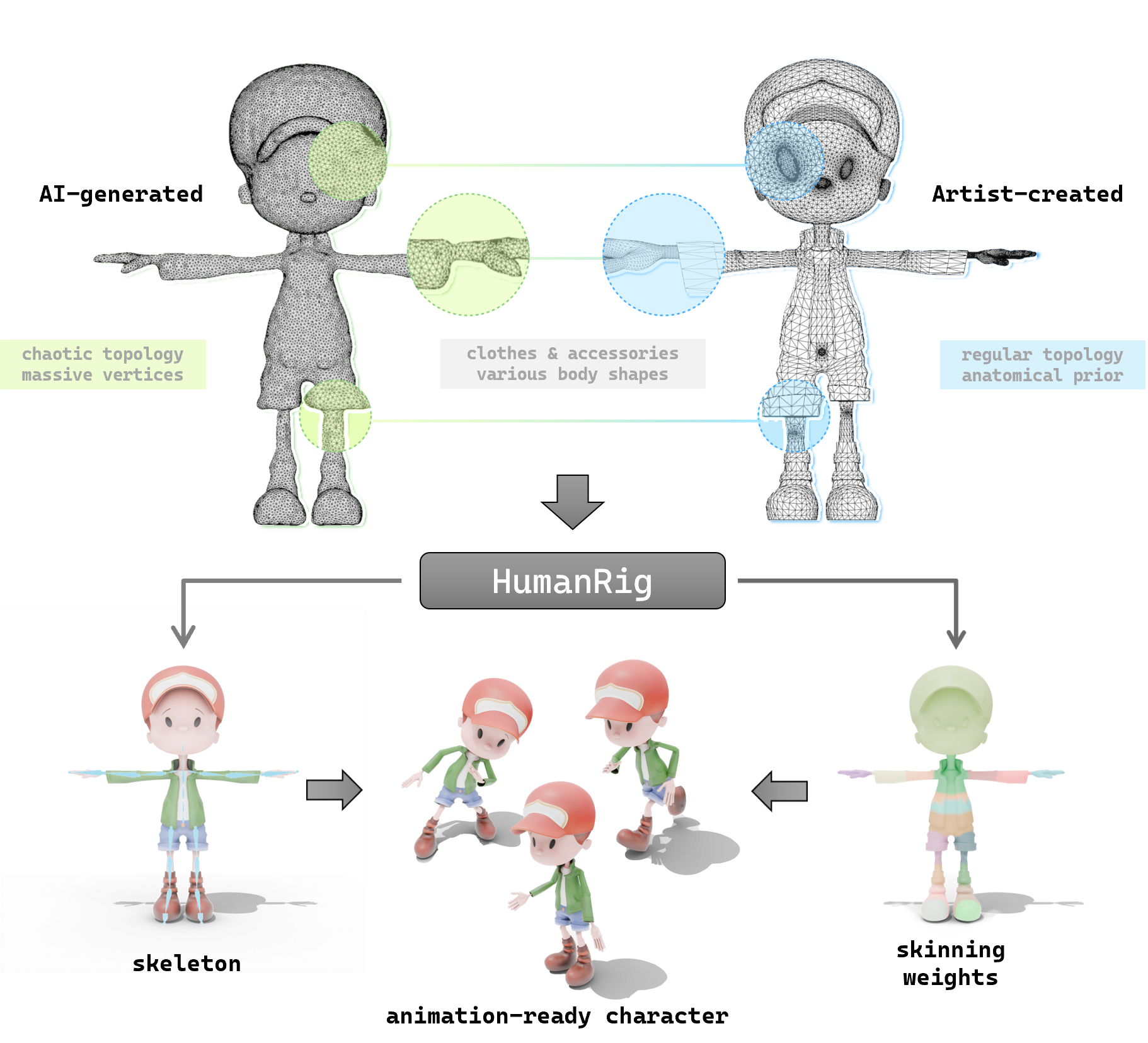
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器
2025年04月22日
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日