Firecrawl:把网页变成AI的“营养餐”,轻松爬取与解析的开源神器

如果你是个对AI开发感兴趣的程序员,或者正在为大模型找“干净”的数据而头疼,那今天要介绍的这个开源项目——Firecrawl,可能会成为你的新宠。它是一个由Mendable团队打造的网页爬取与数据提取工具,目标是把杂乱的网页内容转化为AI模型能轻松消化的Markdown或结构化数据。听起来是不是有点酷?让我们来一探究竟,看看这个项目到底有什么魅力!
一、Firecrawl是干什么的?功能与应用场景
简单来说,Firecrawl是一个网页爬取与数据提取的利器,它的核心使命是把任意网站的内容抓下来,清洗干净,变成大语言模型(LLM)喜欢的格式,比如Markdown或JSON。它的功能可以总结为以下几点:
- 网页爬取(Crawl):给Firecrawl一个URL,它就能自动爬取这个网站的所有可访问子页面,连站点地图都不需要!无论是静态页面还是动态渲染的SPA(单页应用),它都能搞定。
- 内容提取(Scrape):不仅能抓网页,还能提取指定内容,比如文章正文、产品信息,甚至可以按照你的要求返回Markdown、HTML或结构化数据。
- 动态交互支持:Firecrawl支持模拟用户操作,比如点击、输入、滚动等,特别适合抓取需要交互才能加载内容的网页。
- 批量处理与搜索:支持批量抓取多个URL,还能结合网页搜索功能,帮你从搜索结果中提取完整内容。
- 结构化数据提取(Extract):通过自然语言提示(Prompt),Firecrawl能智能提取网页中的特定信息,比如“给我抓取所有产品的名称、价格和描述”。
应用场景
Firecrawl的用处非常广,尤其在AI开发领域简直如鱼得水:
- RAG(检索增强生成):为大模型提供高质量的网页数据,增强回答的准确性和上下文。
- 数据收集:帮开发者抓取产品信息、新闻、博客等,喂给AI模型做训练或分析。
- 内容聚合:想做个行业资讯汇总?Firecrawl可以帮你从多个网站抓取最新文章。
- 自动化研究:比如抓取公司官网信息、招聘启事,快速构建市场分析数据集。
一句话总结:Firecrawl就是个“网页数据搬运工”,专为AI开发者省时省力。
二、技术架构:Firecrawl是怎么“炼成”的?
Firecrawl的架构设计非常模块化,既能保证高效运行,又方便开发者扩展。它的核心架构可以大致分为以下几个部分:
- 爬虫核心(Crawler):负责遍历网站,发现所有可访问的URL。它会自动处理反爬机制、动态渲染等问题。
- 抓取模块(Scraper):基于浏览器的抓取引擎(比如Playwright),能模拟真实用户行为,抓取JavaScript渲染的内容。
- 数据清洗与转换:抓到的原始HTML会被解析、清洗,转换为Markdown或结构化数据。这部分用到了Rust实现的解析器,性能极高。
- 任务调度与并发:通过Redis管理爬取任务,支持大规模并行处理,避免重复抓取(缓存机制)。
- API层:提供简单易用的RESTful API,开发者可以用cURL、Python、Node.js等方式调用。
- 提取引擎(Extract):结合LLM(大语言模型),通过提示词实现智能数据提取,特别适合结构化输出。
整个系统跑在Docker上,支持自托管,安全性也有保障(比如SOC2 Type2认证)。可以说,Firecrawl在性能、易用性和扩展性上都下了不少功夫。
三、核心模块实现逻辑:它是怎么工作的?
为了让大家更直观地理解Firecrawl的“魔法”,我们来拆解几个核心模块的实现逻辑:
1. 爬虫模块(Crawl)
Firecrawl的爬虫会从一个起始URL开始,自动发现页面中的链接(<a>标签、JS跳转等),然后递归访问所有子页面。它会:
- 处理robots.txt:遵守网站的爬取规则,避免被封。
- 动态渲染:用Playwright加载JavaScript,确保抓到完整内容。
- 去重与限速:通过Redis缓存已爬URL,避免重复抓取,同时控制爬取频率,防止触发反爬机制。
2. 抓取模块(Scrape)
抓取模块更像一个“精准手术刀”。你给它一个URL和抓取规则(比如只抓正文),它会:
- 用Playwright模拟浏览器,执行点击、滚动等操作。
- 提取指定格式(Markdown、HTML或JSON)。
- 支持“动作序列”,比如“先点击搜索框,输入关键词,再点搜索按钮”。
3. 数据提取(Extract)
这是Firecrawl的杀手锏!通过/extract接口,你可以用自然语言描述想要的数据,比如“提取所有商品的价格和描述”。它会:
- 用LLM解析网页内容,按照你的提示生成结构化输出。
- 支持自定义JSON Schema,确保输出的格式符合你的需求。
- 自动处理分页、子链接等复杂场景。
简单来说,Firecrawl把爬虫、抓取和智能提取融为一体,开发者只需要调用API,就能拿到干净的数据。
四、使用的技术栈:现代化的开发组合
Firecrawl的技术栈非常现代化,既保证了性能,也方便开发者上手:
- 后端:Node.js + TypeScript,构建高性能的API服务。
- 解析器:Rust实现的HTML解析器,速度快、内存占用低。
- 浏览器引擎:Playwright,用于动态网页抓取。
- 任务队列:Redis,管理爬取任务和缓存。
- 数据库:Supabase(可选),用于存储爬取元数据。
- SDK支持:提供Python、Node.js、Go等多种语言的SDK。
- 部署:Docker + Docker Compose,支持一键部署。
- AI集成:支持OpenAI、Claude等LLM,用于智能提取。
开源协议是AGPL-3.0,社区活跃度很高(GitHub上35k+星),说明它得到了不少开发者的认可。
五、上手难度:新手友好吗?
对于有一定编程基础(比如会用Python或Node.js)的开发者来说,Firecrawl的上手难度可以说是中等偏低。具体分析一下:
优点:
- 文档详细:官网(https://docs.firecrawl.dev)提供了丰富的API文档和代码示例,基本可以“复制粘贴”上手。
- SDK友好:Python和Node.js的SDK封装得很完善,几行代码就能完成抓取任务。
- 免费试用:Firecrawl提供免费额度,适合小规模测试。
- 社区支持:GitHub issue和Discord社区很活跃,遇到问题能快速找到答案。
挑战:
- 配置环境:如果选择自托管,需要懂点Docker和Redis的配置,可能对纯前端开发者有点门槛。
- 动态抓取:想抓复杂网页(比如需要登录或交互),得写点动作序列的逻辑,稍微复杂点。
- API密钥:需要注册账号获取API密钥,免费额度有限,规模大了可能得付费。
总的来说,只要你会基本的HTTP请求和JSON处理,10分钟就能跑通一个简单的爬虫Demo。自托管的话,可能得花1-2小时配置环境。
快速上手示例(Python)
python
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="你的API密钥")
url = "https://example.com"
data = app.scrape_url(url, {"formats": ["markdown"]})
print(data["markdown"])就这么几行代码,你就能把一个网页抓下来,拿到干净的Markdown!
六、与其他项目的对比:Firecrawl有何不同?
市场上类似的爬虫工具有不少,比如Scrapy、BeautifulSoup、Selenium,甚至还有Jina Reader这样的AI爬虫。Firecrawl的独特之处在哪呢?
1. 对比Scrapy
- Scrapy:功能强大但上手复杂,适合专业爬虫工程师。需要自己写爬虫逻辑,处理动态内容得另外集成Selenium。
- Firecrawl:开箱即用,API调用简单,动态内容和数据清洗都内置好了,适合快速开发。
2. 对比BeautifulSoup
- BeautifulSoup:轻量级解析库,适合小规模抓取,但无法处理JavaScript渲染。
- Firecrawl:内置浏览器引擎,能抓动态网页,还支持结构化提取,功能更全面。
3. 对比Selenium
- Selenium:适合自动化测试和复杂交互,但代码量大,维护成本高。
- Firecrawl:通过动作序列实现类似功能,代码更简洁,性能优化更好。
4. 对比Jina Reader
- Jina Reader:专注为RAG提供网页数据,偏向简单抓取和Markdown输出。
- Firecrawl:功能更丰富,支持批量抓取、结构化提取,还能结合LLM做智能解析,适合更复杂的场景。
总结一句:Firecrawl在易用性、功能全面性和AI集成上找到了一个很好的平衡点,既适合快速原型开发,也能应对大规模数据抓取。
七、总结:为什么值得一试?
Firecrawl就像一个“网页数据的魔法师”,帮你把杂乱的网页变成AI模型的“营养餐”。它的核心优势在于:
- 功能强大:爬取、抓取、提取一站式解决,还支持动态网页和智能解析。
- 简单易用:API和SDK设计得很友好,新手也能快速上手。
- 现代化技术:Rust、Playwright、Redis等技术栈保证了性能和扩展性。
- 开源活跃:35k+ GitHub星,社区支持给力,未来可期。
如果你正在为AI项目找数据,或者想快速抓取网页内容做点有趣的应用,不妨试试Firecrawl。只需要几行代码,你就能感受到它带来的效率提升!
最后,感兴趣的朋友可以去GitHub(https://github.com/mendableai/firecrawl)给个Star,或者直接上官网(https://firecrawl.dev)注册试用。有什么好玩的用例,欢迎在评论区分享哦!
参考资料:
- Firecrawl GitHub仓库:https://github.com/mendableai/firecrawl[](https://github.com/mendableai/firecrawl)
- Firecrawl 官方文档:https://docs.firecrawl.dev

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日
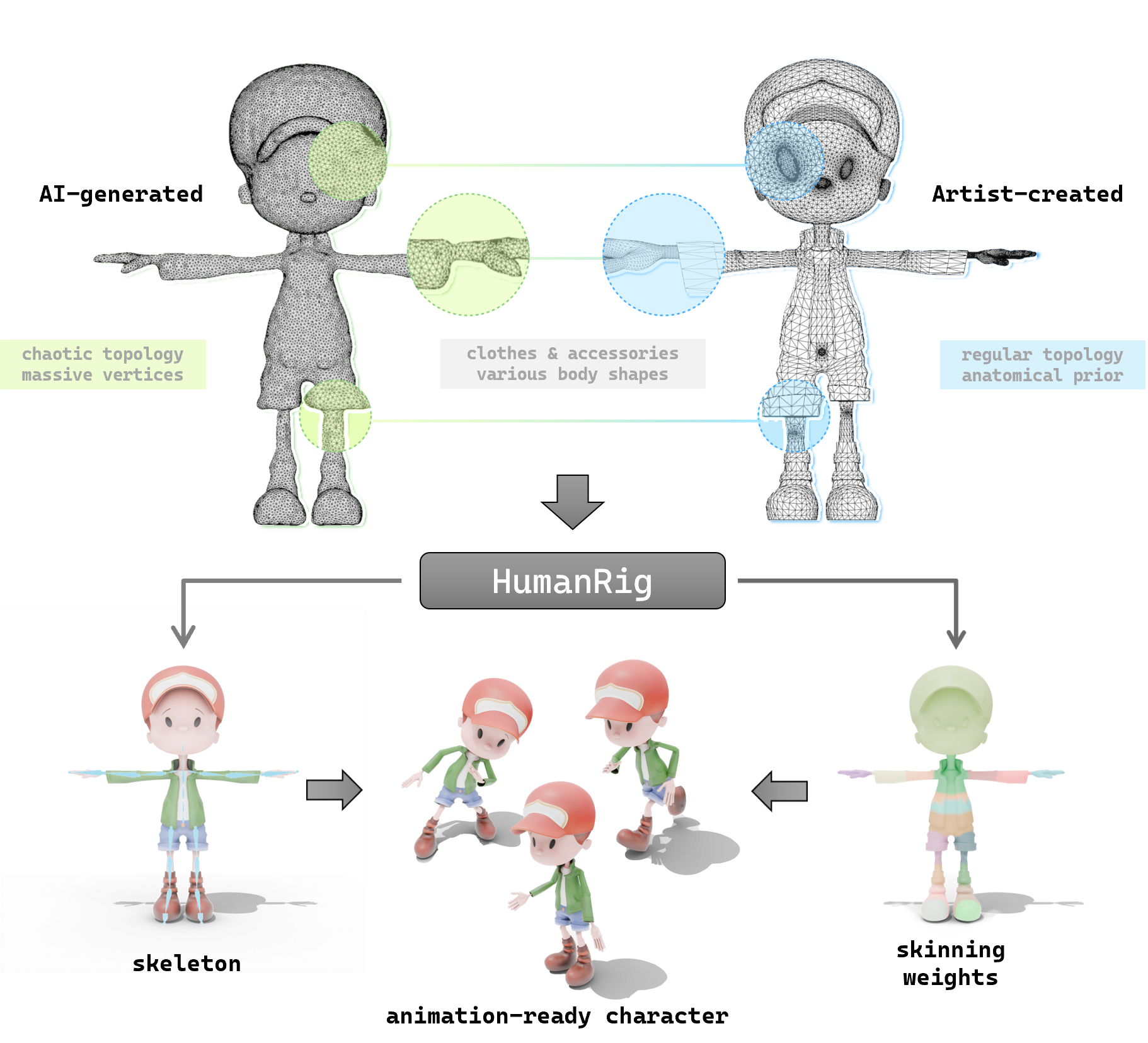
探索 HumanRig:让 3D 角色动画更简单的开源神器
2025年04月20日

探索 so-vits-svc:让你的动漫角色开口唱歌的 AI 神器
2025年04月22日
Suna 开源项目介绍:通用 AI 代理的轻松上手指南
2025年04月23日