LLaMA-Factory:一键微调百种大模型的开源利器

想让大语言模型(LLM)听你的话?还是希望用最简单的方式打造一个专属 AI?GitHub 上的开源项目 LLaMA-Factory(https://github.com/hiyouga/LLaMA-Factory)可能是你的最佳选择!这个项目号称“LLM 微调工厂”,支持超 100 种模型,操作简单到连新手都能快速上手。今天我们就来聊聊 LLaMA-Factory 的功能、技术细节和上手体验,看看它如何让 AI 微调变得像搭积木一样轻松!
一、LLaMA-Factory 能干啥?功能与应用场景
LLaMA-Factory 是一个专注于大语言模型和多模态模型高效微调的开源框架。它的核心目标是让开发者以最小的成本和代码量,快速定制专属模型。以下是它的主要功能:
- 支持超 100 种模型:从 LLaMA、Mistral 到 Qwen、Grok,涵盖语言模型和视觉语言模型(VLM),几乎你能想到的热门模型都能微调。
- 多种微调方式:支持全参数微调(Full Fine-Tuning)、LoRA(低秩适配)、QLoRA(量化 LoRA),以及 DPO、RLHF 等高级优化方法。
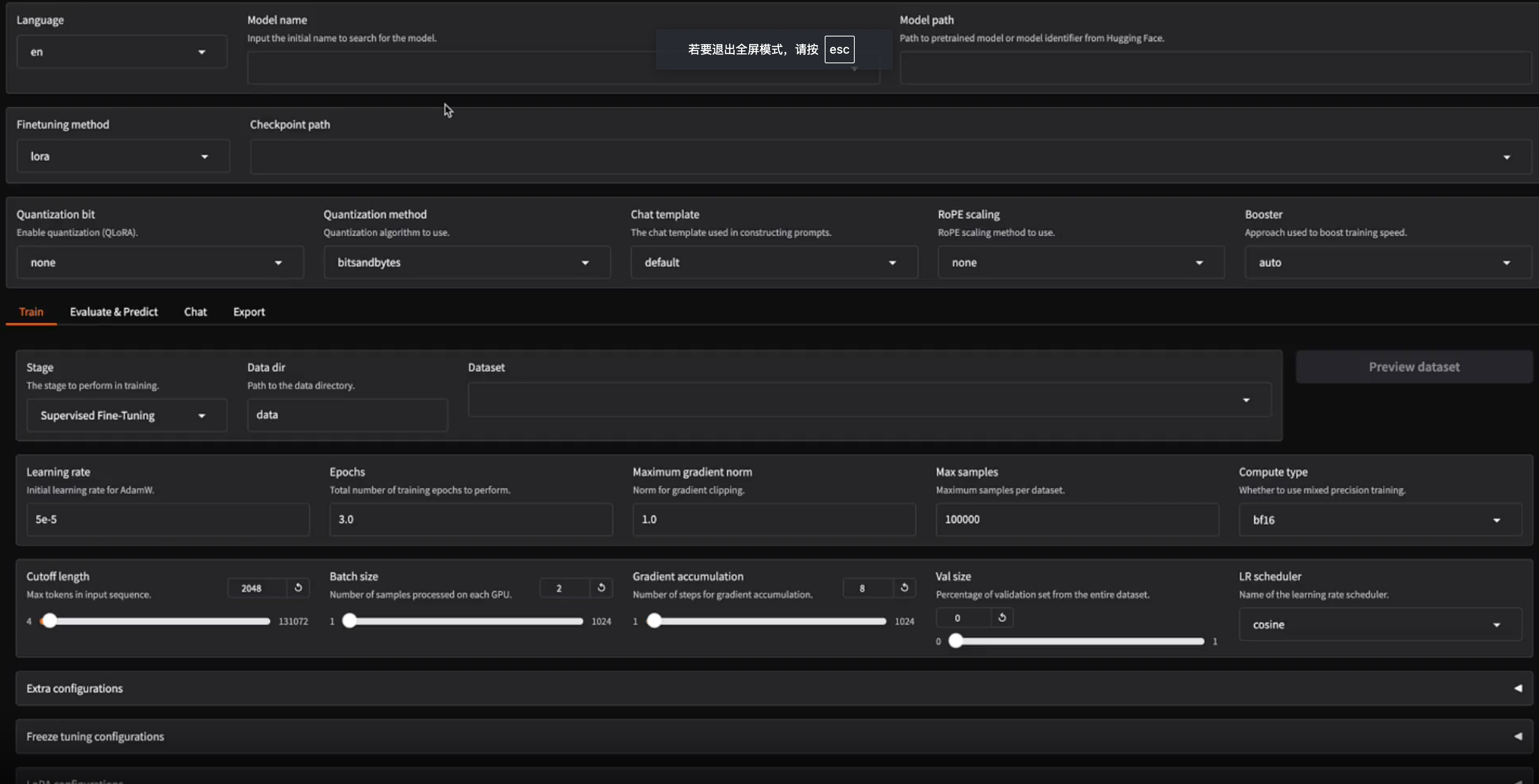
- WebUI 界面:提供图形化界面(LLaMA Board),无需敲代码,点点鼠标就能完成微调、推理和模型导出。
- 高效训练:通过 4 位量化、FlashAttention-2 等技术,降低显存占用,即使单张消费级 GPU(如 RTX 3060)也能跑大型模型。
- 多模态支持:不仅能微调文本模型,还支持图像、视频等多模态输入,适合打造多才多艺的 AI。
应用场景
- 个性化 AI 助手:用公司内部数据微调一个专属客服或知识库助手,提升回答准确性。
- 学术研究:AI 研究者可以用它快速实验不同模型和微调策略,验证新算法。
- 内容创作:微调模型生成特定风格的文章、代码或广告文案,省时省力。
- 多模态应用:结合图像和文本,打造能“看图说话”的虚拟主播或智能客服。
- 教育与学习:学生和开发者可以用它学习 LLM 微调原理,边玩边学。
简单来说,LLaMA-Factory 就像一个“AI 定制工厂”,不管你是想做实用工具还是搞研究,它都能帮你省下大把时间。
二、技术架构:LLaMA-Factory 的“魔法”怎么实现的?
LLaMA-Factory 的强大离不开其模块化设计和对主流 AI 技术的整合。它的技术架构可以拆解为以下几个部分:
- 模型加载与管理:通过 Hugging Face 的
transformers库,动态加载预训练模型(如 LLaMA、Qwen),支持多种量化格式(4-bit、8-bit)。 - 微调策略:核心微调方法基于 LoRA 和 QLoRA,利用
peft库实现高效参数更新,降低显存需求。 - 数据处理:支持多种数据集格式(如 Alpaca、ShareGPT),内置数据预处理模块,自动分词、截断和对齐。
- 训练优化:集成 DeepSpeed、FlashAttention-2、Liger-Kernel 等加速技术,优化训练速度和显存占用。
- 推理与部署:支持 vLLM、SGLang 等推理框架,微调后的模型可一键导出到 Hugging Face 或 OpenAI API 格式。
- WebUI:基于 Gradio 开发的 LLaMA Board,提供模型选择、参数配置和实时监控功能,降低操作门槛。
整体流程是:选择模型和数据集 → 配置微调参数(LoRA 秩、学习率等) → 启动训练(命令行或 WebUI) → 输出微调模型 → 推理或部署。整个过程高度自动化,灵活性极高。
三、核心模块的实现逻辑
为了让大家更清楚 LLaMA-Factory 的工作原理,我们来拆解几个核心模块:
-
模型加载(Model Loading)
- 逻辑:通过
AutoModelForCausalLM和AutoTokenizer加载预训练模型和分词器,支持 Hugging Face Hub 或本地路径。 - 实现:代码调用
transformers库,自动适配模型架构(如 LLaMA、Mistral)。对于量化模型,使用bitsandbytes库加载 4-bit 或 8-bit 权重。 - 关键点:支持动态加载,兼容多种模型格式,显存占用可通过量化大幅降低。
- 逻辑:通过
-
微调策略(LoRA/QLoRA)
- 逻辑:LoRA 在预训练模型的基础上添加少量可训练参数(低秩矩阵),QLoRA 进一步通过量化降低显存需求。
- 实现:基于
peft库,代码自动为指定层(如 attention、feed-forward)插入 LoRA 适配器。训练时只更新 LoRA 参数,冻结原始权重。 - 关键点:LoRA 秩(
lora_rank)和目标模块(lora_target)可自由配置,微调 7B 模型只需 6-8GB 显存。
-
数据处理(Dataset Processing)
- 逻辑:将输入数据集(如 JSON、CSV)转换为模型可用的格式,处理多轮对话、多模态输入等。
- 实现:内置模板(如
llama3、qwen)处理对话格式,使用datasets库并行预处理,支持自定义数据集。 - 关键点:支持 ShareGPT 格式(多角色对话)和多模态数据(如图像+文本),预处理速度快。
-
训练与优化(Training Pipeline)
- 逻辑:通过
transformers.Trainer或自定义llamafactory-cli协调训练,优化显存和速度。 - 实现:集成 DeepSpeed(分布式训练)、FlashAttention-2(加速注意力计算)、Unsloth(异步优化)等技术,损失函数支持 SFT、DPO 等。
- 关键点:训练过程可实时监控损失曲线,自动保存检查点,失败后支持断点续训。
- 逻辑:通过
-
WebUI(LLaMA Board)
- 逻辑:提供图形化界面,封装命令行操作,用户只需选择模型、数据集和参数。
- 实现:基于 Gradio,调用后端 Python 脚本(
llamafactory-cli),支持远程部署(通过GRADIO_SHARE=1)。 - 关键点:零代码体验,适合初学者,同时支持命令预览,方便开发者调试。
四、用到的技术栈
LLaMA-Factory 的技术栈非常现代化,覆盖了 AI 开发的方方面面。以下是主要技术点:
- 编程语言:Python 3.8+(推荐 3.10)
- 核心框架:
transformers:模型加载和推理peft:LoRA 和 QLoRA 实现bitsandbytes:4-bit/8-bit 量化datasets:数据集处理
- 加速技术:
- DeepSpeed:分布式训练
- FlashAttention-2:高效注意力机制
- Liger-Kernel、Unsloth:训练优化
- 推理框架:
- vLLM:高效推理
- SGLang:结构化生成
- 前端界面:
- Gradio:WebUI 开发
- 其他依赖:
torch:PyTorch 框架huggingface_hub:模型和数据集下载wandb、tensorboard:训练监控(可选)
代码结构清晰,src/llamafactory 包含核心逻辑,examples 提供多种配置文件(如 LoRA、DPO),适合二次开发。
五、上手难度:小白能玩转吗?
LLaMA-Factory 的上手难度属于低到中等,对 Python 开发者非常友好,零基础用户通过 WebUI 也能快速入门。以下是详细分析:
安装步骤
- 环境准备:安装 Python 3.10、Git 和 PyTorch(支持 CUDA 或 Ascend NPU)。
- 克隆仓库:运行
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git。 - 安装依赖:进入目录,运行
pip install -e ".[torch,metrics]"。Windows 用户可能需额外安装bitsandbytes。 - 启动 WebUI:运行
llamafactory-cli webui,浏览器打开即可操作。 - 命令行微调:编辑
examples/train_lora/llama3_lora_sft.yaml,运行llamafactory-cli train <配置文件>。
可能遇到的坑
- 显存要求:微调 7B 模型推荐 12GB 显存,QLoRA 可降至 6GB,但 CPU 运行极慢。
- 依赖冲突:PyTorch 版本需与 CUDA 匹配,建议用虚拟环境(
venv或conda)。 - Hugging Face 访问:部分模型需要登录 Hugging Face(
huggingface_hub.login)或科学上网。 - 多模态支持:微调 VLM(如 Qwen2-VL)需要
transformers>=4.35.0,可能需手动升级。
好消息
- WebUI 零代码:LLaMA Board 让微调像玩游戏一样,选模型、点参数、点“Start”就行。
- 文档完善:官方 Wiki 和
README提供了详细教程,社区(GitHub Issues)活跃,问题容易解决。 - 示例丰富:
examples文件夹包含多种场景的配置文件,直接改改就能用。
总结:有 Python 和 PyTorch 基础的朋友,1 小时内就能跑通 demo。完全零基础的用户,跟着 WebUI 教程也能在半天内上手。
六、和其他项目的对比
LLaMA-Factory 不是唯一的微调框架,我们来对比几个类似项目,看看它的独特之处:
-
DeepSpeed(微软)
- 优点:分布式训练效率高,适合超大规模模型。
- 缺点:配置复杂,缺乏 WebUI,主要面向专业团队。
- 对比:LLaMA-Factory 集成了 DeepSpeed 的优点,同时提供简单接口和 WebUI,适合个人开发者。
-
Axolotl
- 优点:支持 LoRA、QLoRA,配置文件灵活,社区活跃。
- 缺点:无图形界面,学习曲线稍陡,文档不如 LLaMA-Factory 友好。
- 对比:LLaMA-Factory 的 WebUI 和多模态支持更适合新手,模型覆盖更广。
-
Unsloth
- 优点:训练速度快,显存优化强,适合消费级硬件。
- 缺点:模型支持较少(主要 LLaMA 系列),功能单一。
- 对比:LLaMA-Factory 集成了 Unsloth 的优化,同时支持更多模型和微调方式。
-
Hugging Face Transformers
- 优点:生态完善,模型支持最全,适合深度定制。
- 缺点:微调代码需手动写,门槛较高,无内置 WebUI。
- 对比:LLaMA-Factory 基于 Transformers 封装了微调流程,省去大量代码工作。
-
商业平台(如 RunPod、Replicate)
- 优点:无需本地配置,云端一键微调。
- 缺点:成本高,数据隐私存疑,不开源。
- 对比:LLaMA-Factory 完全开源,免费且灵活,数据本地化更安全。
总的来说,LLaMA-Factory 在易用性、模型支持和功能全面性上表现突出,尤其适合想快速上手又不失灵活性的开发者。
快去 GitHub 克隆一份代码,微调一个属于你的 AI 吧!有什么好玩的微调成果,欢迎在评论区分享哦~
(本文部分信息参考自 LLaMA-Factory 的 GitHub 页面和社区讨论,感谢 hiyouga 和开源社区的贡献!)

AutoGPT:让AI帮你“自动搞定一切”的开源神器
2025年04月11日

LLMs-from-Scratch:从零打造ChatGPT的开源教科书
2025年04月13日

Open-Assistant:打造开源的“未来助手”,对话AI的平民革命!
2025年04月13日
GPT-Pilot:你的AI编程助手,带你从零打造应用!
2025年04月19日
LocalAI:你的本地AI神器,轻松打造专属智能应用!
2025年04月19日
FramePack:让视频生成像玩游戏一样简单!
2025年04月20日
MCPO:让 AI 工具秒变 RESTful API 的“魔法桥梁”!
2025年04月20日

GigaTok:扩展视觉标记器至 30 亿参数用于自回归图像生成
2025年04月20日

大模型的新突破:LiveCC 让“直播 AI 解说”成为现实
2025年04月25日